
A Compendium on Synthetic Data Projects
Knowledge that is both necessary and expansive, learned independent of experience

Here's the thing about data in 2024: we're all simultaneously drowning in it and desperately searching for more of it. It's like that time in the '90s when everyone suddenly needed a website but nobody knew exactly why—except this time, we actually know why. We need data. Lots of it. Clean, unbiased, privacy-compliant data that doesn't cost a fortune or require signing away your firstborn to some shadowy data broker in Estonia. Synthetic data can be the digital equivalent of lab-grown diamonds, except instead of destroying the De Beers monopoly, it could help accelerate AI development.
As I sit here in my slightly-too-cold home office (my smart thermostat is apparently going through an energy-saving phase), I can't help but marvel at how we've gone from manually labeling datasets to literally teaching machines to dream up their own training data. In this deep dive, I am exploring several projects that I found interesting that are turning this SciFi concept into reality. I hope you come to think of this as your guide through the looking glass of synthetic data, where the ones and zeros are made up, but the implications might be real.
This post has three subsections for my chosen synthetic data projects.
Framework and Tools
Learning Methods
Reasoning
Frameworks & Tools
AgentInstruct | Paper
Arindam Mitra, Luciano Del Corro, Guoqing Zheng, Shweti Mahajan, Dany Rouhana, Andres Codas, Yadong Lu, Wei-ge Chen, Olga Vrousgos, Corby Rosset, Fillipe Silva, Hamed Khanpour, Yash Lara, Ahmed Awadallah
The first project I am introducing today is AgentInstruct which introduces an agentic framework for automatically creating large amounts of diverse and high-quality synthetic data. The team's dataset can be used for general instruction tuning of base models.
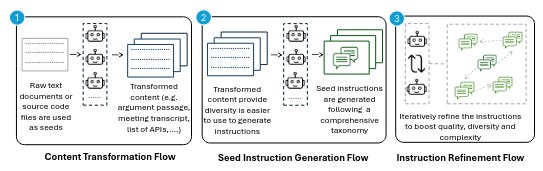
Given this framework, AgentInstruct can be used to synthesize both prompts and responses when raw data sources like text/code documents are used as seeds. Through this, the team created a post-training dataset of 25M pairs that can be used to teach language models skills like text editing, creative writing, tool usage, coding, and reading comprehension.
DataDreamer | Paper
Ajay Patel, Colin Raffel, Chris Callison-Burch
Next up is DataDreamer, an open-source Python library that allows you to implement LLM synthetic data workflows with only a few lines of code. In my opinion, DataDreamer’s biggest flaw is that it relies on OpenAI for most of the heavy lifting. I don’t have anything against OpenAI, but if I want to create data, I might have to run it a couple of times on a short sample until I get the prompt and the quality right. Then I would run it on a large dataset to apply the working model. Paying every time for this would not be in the spirit of “open source”. It is still an interesting approach worthwhile to explore further.
source
{kind=link}
Distilabel | Paper
This project aims to provide a framework for the creation of synthetic data. It aims to be used for a wide variety of projects including traditional predictive Natural Language Processing tasks like classification or extraction. But also generative and large language model scenarios like instruction following, dialogue generation, or judging. I think the most interesting part of this project is their “cookbooks” like this one for structured JSON generation. What I like about this project is that they also include local LLMs in their cookbooks.
Learning Methods
Persona Hub | Paper
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, Dong Yu

source - page 1
This project I really interesting from a digital twin or Anthropic’s personality concept perspective since the persona-driven data synthesis methodology can create truly diverse synthetic data. This insight was inspired by the observation that simply adding a persona to the data synthesis prompt can steer the LLM towards the corresponding perspective to create truly distinct synthetic data. The team has developed two distinct methods to create learning data 1. Text-to-Persona and 2. Persona-to-Persona.

Of course, it looks simplistic if broken down to that level, but I think the paper is well written, and given the research by Anthropic basing the model in a persona, it might be a productive approach.
ToolAlpaca | Paper
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, Le Sun
One of the problems I frequently run into is that my local LLMs can’t use a customer tool I have defined. ToolAlpaca is a framework that aims to help smaller LLMs learn generalized tool-use abilities with minimal human supervision. It approaches the problem by generating a tool-use corpus via a multi-agent simulation environment, providing 3.9k tool-use instances from more than 400 tools.
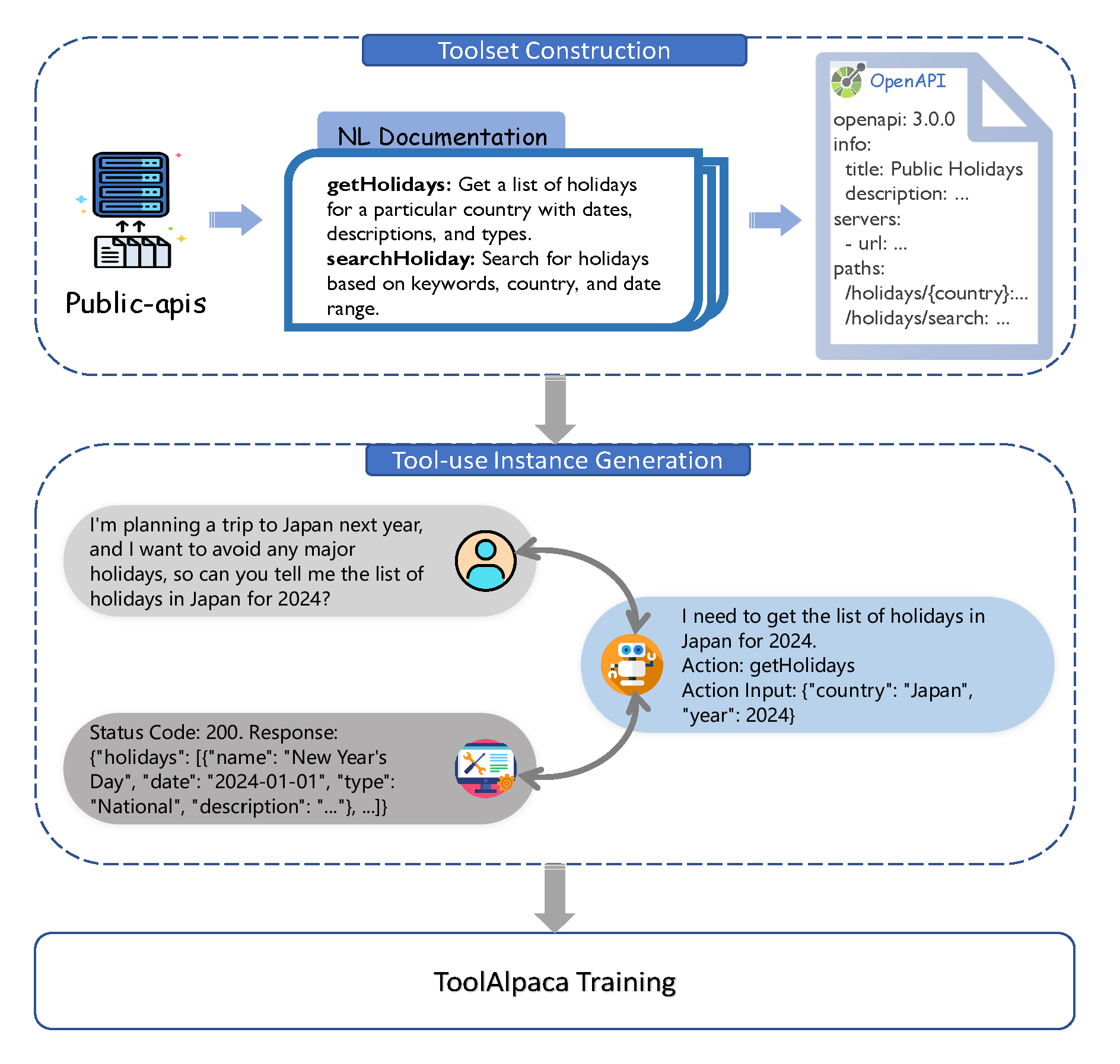
Reasoning
STaR | Paper
Eric Zelikman, Yuhuai Wu, Jesse Mu, Noah D. Goodman
The STaR paper approaches the problem of creating synthetic data for reasoning by “Bootstrapping Reasoning With Reasoning”. Might sound counterintuitive. The team leverages a technique to iteratively apply a small batch of rationale examples and a large dataset without rationales, to bootstrap the ability to perform successively more complex reasoning.
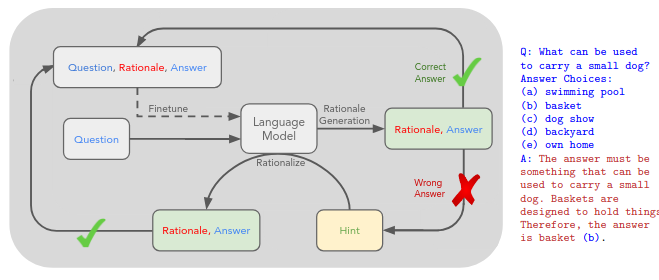
This technique, the "Self-Taught Reasoner" (STaR), relies on this simple loop: generate rationales to answer many questions, prompted with a few rationale examples; if the generated answers are wrong, try again to generate a rationale given the correct answer; fine-tune on all the rationales that ultimately yielded correct answers; repeat. Fantastic.
MetaMath | Paper | Data
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, Weiyang Liu
Mathematical reasoning is an interesting problem for LLMs because Neural Networks are generally bad at basic math. Now the research team has created a synthetic dataset called MetaMathQA that can fine-tune a language model for specialization in mathematical reasoning. The team bootstrapped mathematical questions by rewriting the question from multiple perspectives without extra knowledge.

source - page 1
The team applied the dataset on LLaMA-2 models and could demonstrate that based on two popular benchmarks (GSM8K and MATH) for mathematical reasoning their MetaMath model outperforms a suite of open-source LLMs by a significant margin.
MathGenie | Paper
Zimu Lu, Aojun Zhou, Houxing Ren, Ke Wang, Weikang Shi, Junting Pan, Mingjie Zhan, Hongsheng Li
The last project I will introduce is MathGenie. That project aims to provide a method for generating diverse and reliable math problems from a small seed problem-solution dataset. Similar to the Persona project, this seed should provide a ground truth to the model that can then me used to train a back-translation model that translates the augmented solutions back into new questions.
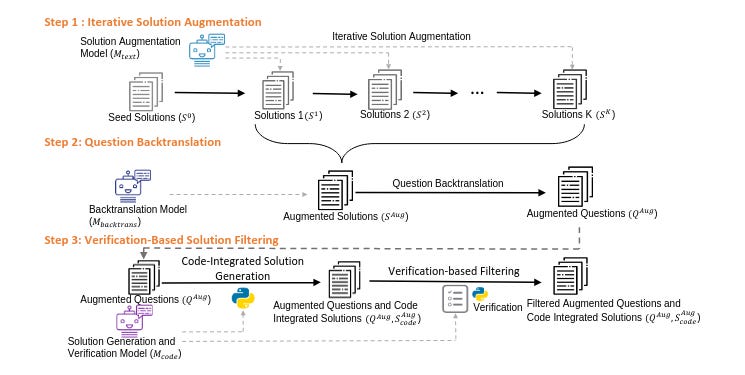
source - page 2
With the newly created data, the team trained a selection of pre-trained models, ranging from 7B to 70B, to test the effectiveness of the proposed augmentation technique. The result of this post-training reasoning technique is MathGenieLM.
I hope you enjoyed this little overview of synthetic data projects.
Have a great start to the new week!
