Synthetic Data: Enhancing AI Training and Ensuring Data Privacy
Applications and Tools towards building Financial AI Agents

After about 15+ years of working with data in multinational Financial Services Enterprises and Startups, ranging from multi-billion dollar portfolio’s consisting of financial data, news articles, politician trades, calendar information, to social media posts for sentiment analysis, I learned one thing.
Financial data is ultra-complex, flows in high velocity, is highly varied, and heavily regulated especially if you consider personal information.
So why on earth would anyone think about adding to this plethora of data the use-case of synthetic data?
Well, largely because there are value-adding applications for them.
Applications of Synthetic Data in Risk Management
Not an exhaustive list by any means.
Traditionally the main purpose of synthetic data is to create user profiles that behave similar to actual user data to ensure compliance with data protection regulations.
However, there is more. The way I used synthetic data in my professional past included these applications.
Scenario Analysis/Portfolio Optimization: Here synthetic data for is the artificial creation of transaction data that mimics our existing actual financial data to understand effects of new portfolios that might be acquired and needed to be back tested. And also to verify how portfolios might react to external shocks. Here techniques like measuring the Wasserstein distance or Kolmogorov-Smirnov tests helped to quantify if the distributions are similar across dimensions.
Credit Scoring and Loan Origination: When I was the CRO of a multi-billion dollar lending business, we did not use synthetic data for this purpose. The main reason was that there are reasons why customers default and by understanding their specific stories and reasons did help us understand our portfolio better and also make sure that our policies are forward looking and protecting our customers while also protecting us. However, during scorecard development I can see that the development teams do not need to see customer identities, here creation of digital clones might be helpful.
Fraud Detection and Anti-Money Laundering (AML): AML and Fraud models are traditionally outlier models. Here, synthetic data can help to ensure operations are up to par with regulations. Typical operational aspects include suspicious activity detection, transaction modeling, and model validation.
Data Bias Reduction: Also, a common theme that proponents of synthetic data commonly mention. However, I believe that bias in data is not necessarily bad, and it usually should trigger an investigation if a model behaves in a certain way. That way the teams learn more about the business and customer’s needs rather than simply ignoring it. I believe it’s an important part of capability development within an organization.
Given that I could prove to you that there is value in synthetic data.
How can we generate it?
Synthetic Data Generation with Python
There are several Python libraries available for synthetic data generation, each with its distinct capabilities and features.
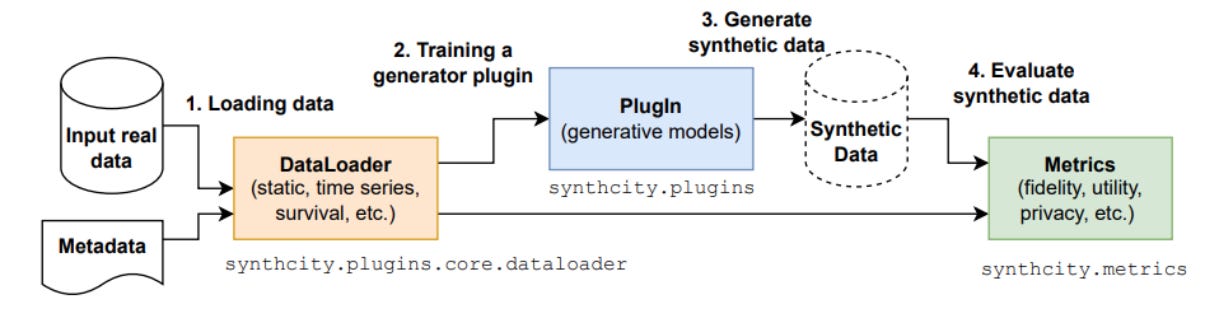
SynthCity: A now commercial python-based product created by van der Schaar Labs, SynthCity is used for the generation and evaluation of primarily synthetic tabular data. The package however also offers a plugin architecture and a wide array of reference models that range from GAN-based methods to Bayesian Networks. With the latter ones being used for time series, survival analysis, and privacy-centric synthesis.