
Nemotron vs Qwen - Game Theory and Agent Reasoning IV
Battling Two Popular Agent Models In An Epic Battle To The Death

Neon signs pulse in the grey drizzle outside, their glow bleeding onto the game board —a city of endless moves and opportunities.
AI in gaming isn’t new; it’s been around for decades. In fact, the first in-game AI was built in 1948 for a game called “Nim”. Machines playing chess at grandmaster levels without search? 10 years ago. However, most gaming AI is narrow. I.e., it is specifically developed and trained for this one purpose and this special purpose alone. As BiggestTech is working towards AGI, I was wondering what happens when we take a new approach that does not rely on specially designed brute-forcing all possible outcomes but instead applies general situational reasoning.
Are current-gen free models reliable enough for general decision-making?
Gameplay
How capable are generic pre-trained LLMs in analyzing and “understanding” any state the game is in?
How accurate is the analysis of the game state?
Do they, similar to us humans, block an obvious losing situation?
Do they lock in an obvious win?
Reliability
Is a reliable game possible?
What failure modes occur most often?
How many errors do they make in “reading” the board situation?
How many errors occur when selecting a board situation?
Performance
After how many iterations do they reach a result?
Do they reach a conclusion at all?
How long does one “move” take?
Is the reasoning correct?
As usual, the code and data will be made available to paying users in chat.
Setup
For this exercise, I am using two pre-trained generic off-the-shelf LLMs, embed them in an agent framework, and provide them with all the information they need to make a decision. Furthermore, both LLM are given the exact same task. Both models use the default system prompt. Both LLMs are rewarded for their win. This approach is not reinforcement learning, at least not in the classical sense. But the concept feels close—a structured incentive to engage, adapt, and respond. Both LLMs are not given few-shot examples.
Here is a draft of the game loop:
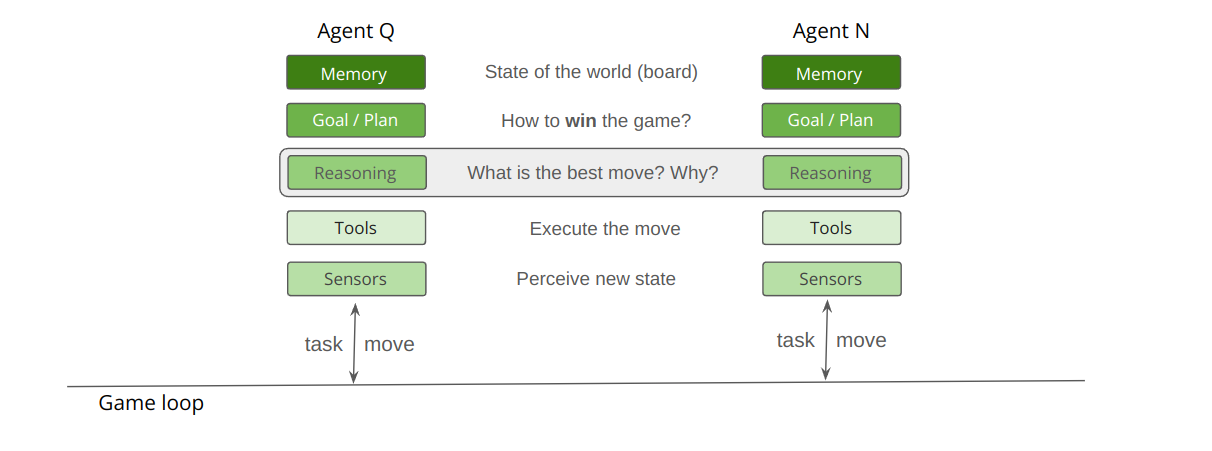
The first agent will be “Qwenny” a ReAct-pattern agent based on the popular Qwen-2.5 72B model. And the other agent will be “Nemo” based on the recently announced Nvidia Nemotron 70B model.
These two agents played 100 rounds of a Tic Tac Toe-like board game. Fundamentally, they are reasoning over a matrix structure which, as a use-case, can be generalized even further. For the measurement of outcomes, it didn’t matter who won as I was only interested in the “how” and “why” and not the “what”.
The game board was defined as 4x4 to prevent models using a pre-trained knowledge of Tic Tac Toe. Any mentions of “Tic Tac Toe have” been removed from the task prompt since this has led to the agent erroneously using a 3x3 “state of mind”. For example, when there were two XX next to each other the agent assumed that only one additional X would be necessary to win the game.
No few-shot examples had been provided. I also did not use a dedicated memory outside of the session memories the agents already have.
Both agents were provided the current state of the board as a matrix, a list of valid positions, and their player symbol to make a decision.
Huggingface Agents
Again, I selected a personal favorite — the Transformers framework to build the agents. I think in general, this framework is easy enough to implement, I can easily integrate higher performing models remotely, their free plan is generous, I can track all the calls that are made, and now they also store their “thought” process in an easily accessible log.
Especially the last point is, in my opinion, really important for agent governance.
Here is an example how an abbreviated thought response looks like:

In case you are wondering how you get access to this information from your agent objects programmatically; these objects can be accessed like this:
Task: self.agent.task, and Log: self.agent.logs
I think the data structure is well enough designed and provides the information needed to evaluate the model’s performance.
Model Selection
I already used Qwen2.5 in a previous exercise and in general, liked its performance. However, when I started running the exercise, I ran into massive API issues where the model was frequently overloaded. Even though I am on the pro plan, there is an operational risk when running your models in a production workflow in this way. Therefore, I used here the Coder model and not the Instruct model. Explanation follows.
As its opponent, I selected the new Nvidia Nemotron model which was touted to have reliable tool calling and good reasoning. Also, I would hope that selecting this one helps with the SEO for the article. Initially, I wanted to use the QwQ model, but I never got it to reliably play the game.
As part of its agent framework, transformers offers two different types of agents ReactJsonAgent and ReactCodeAgent.
Therefore, I decided to enforce JSON dictionaries with the Coder model.
Pydantic
Reliability is an issue with many agentic workflow implementations. Many frameworks rely on Pydantic to validate their schema. So I figured I’d do the same.
Here is my schema template :
class MoveResponse(BaseModel):
move: List[int] # Expecting a list of two integers [x, y]
thought: str # A string explaining the moveI use the Pydantic to validate the move template dictionary against the MoveResponse schema. The schema expects a move field as a list of two integers (e.g., [x, y]) and a thought field as a string explaining the move. The line response = MoveResponse(**move) unpacks the dictionary into keyword arguments and checks them against the schema. If the data does not meet the expected format (e.g., incorrect types or missing fields), Pydantic raises a ValidationError, ensuring robust input validation with minimal effort.
I integrated this check in a loop that only breaks if a response is shown to be valid. This loop by definition will run infinitely long and re-query the LLM again. From a governance perspective, it makes sense to ensure that the LLM is given the time to find the right answer. To be clear, in the agent loop, if an error occurred, I provided the error message back to the agent with the instruction to fix it. However, I had to notice that there were scenarios where the agent would never terminate as the response never changed. Therefore, I defined a hard limit of 10 iteration steps and logged this appropriately. Interestingly, in the “live run” on which I am basing this analysis, this only happened three times. Three out of 1,600 is acceptable.
Game logs
I made the agents play exactly 100 rounds. That should in the worst case yield 1,600 entries — all draws — of move decisions for both agents. All decisions the agents took were recorded and later analyzed for :
Was the move correct? I.e., a playable move.
Was the reasoning correct? I.e., did the agent correctly understand the game state and act accordingly?
Did the agent miss an obvious win/loss?
Did the agent correctly block when the agent mentioned that it would do so?
This record was stored in a CSV and then manually evaluated. At some point in time, I was considering using another LLM to critique the move, but this time, I wanted to just get the pure response of the LLMs.
Tracing Thought
With the technique mentioned above, I also stored the “thought” process of the ReAct agents. However, given the outcome of the agent’s final answers, I decided to push this analysis to a later stage.
Results
For the avoidance of doubt, I measured the performance of the response as a human expert. And it was frustrating. It felt like watching two stupid kids play. Especially during mid-game none of the moves looked like they made any sense. And I suppose that is not all too surprising given that we are looking at two machines that do not have the slightest understanding of what they are doing. I think that became quite apparent. However, they are really good at sounding convincing and then executing their moves.
Overall, the Qwen model with first-move advantage won 41 times, the Nemotron model won 21 times, and I observed 38 draws throughout the 100 games. The agents decided on moves 1,349 times. There were only 3 observations where the model would not be able to decide. All of those were by Qwen.
Therefore, it is possible to conduct reliable gameplay with these models, even though they have not been trained specifically on it.
If you consider a heatmap of favorite board situations an interesting pattern emerges.
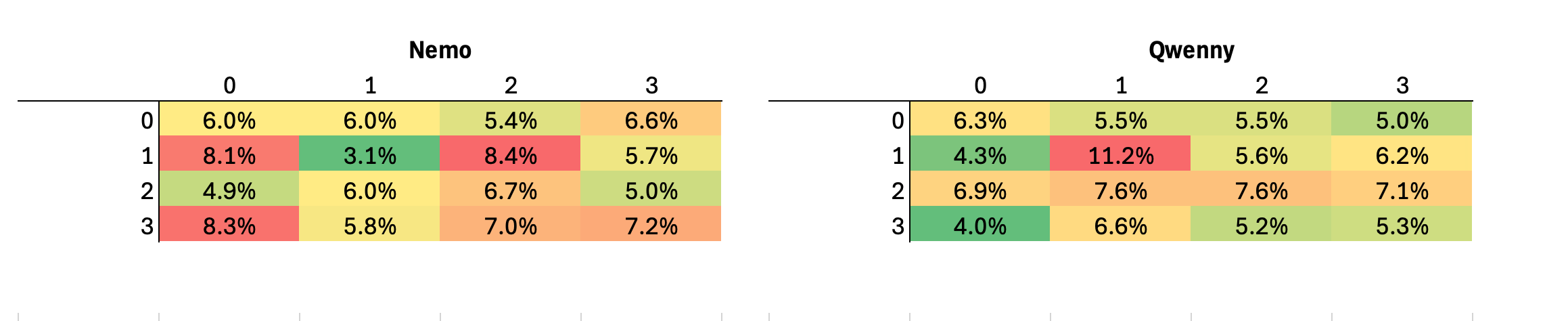
We can observe that Qwen (right) as the opening model prefers to start at [1,1] while Nemo as the second player follows up usually with [1,2] or [1,0].
How do they reason?
Usually, the agents perform much better in reasoning tasks when there is nothing else on the board and towards the end when the state of the board is clear. During mid-game, the agents frequently mixed up rows and columns and referred in their final answer to non-existing board situations. I think that the problem has two sources. First, the models understand tic-tac-toe and tries to apply this knowledge to the situation.
Second, we observe also an encoding problem and it might be worthwhile to vary different game-state encoding techniques like just using a running number [1-16] for each cell.
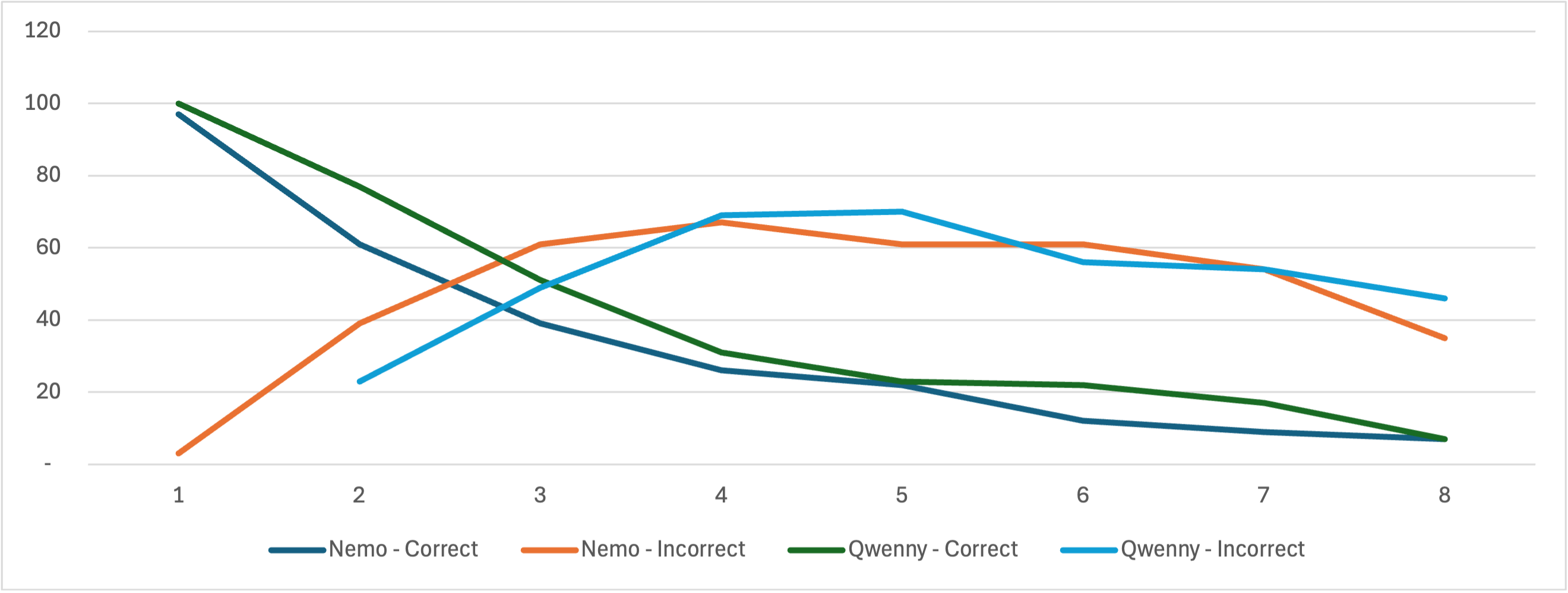
I could observe in a few cases that the agent seemed to correctly “understand” the state of the board and then made the right decision. But how reliable is that? Are these just great fakes or is there something more? This fact should be easily visible when there is an obvious win/lose board situation, and the agent would not decide to execute it.
Here are these numbers:

What I noticed was that the agents more often than not failed to “close the deal” and either successfully block or win the game outright. But there were enough cases where the agent correctly understood the need to block an obvious win and did so. I concluded that for the letter, the game mechanic is close enough to the original rule of Tic Tac Toe and the agent simply applies this than truly reasoning through the task.
We are all middle-managers
As we are closing in on becoming better agent managers, it feels like we are measuring the work performance of an employee. It will be interesting to see how the agent performs given more experience (sequential memory) and better instructions (few-shot examples from synthetic data). Based on the collected data, I will be able to extract a synthetic dataset of thoughts that might be used for few-shot learning to improve reasoning quality. This might help guide future iterations of my agents towards a more robust reasoning.
When you are building agents, there are also other ways to improve the performance of your digital counterparts besides the prompt. For the next iteration, I am to improve the context so the agent has more information about historic moves when making a decision. This also depends on better integrating memory into the workflow. Also, I want to execute the agents in alternating modes to not have one agent at the start advantage all the time.
I believe this exercise outlines the existence of model risk in agentic processes that in many cases we won’t be able to manage properly until we fully understand where it comes from.
And I hope that through this exercise I can develop a better understanding of how to measure it.
