
On Retrieving Relevant Information
Strategies for better knowledge mining: From simple Documents to Agentic RAG and what lies ahead.

I have never been quite satisfied with Retrieval-Augmented Generation (RAG). There is always this lingering doubt in the back of your head that some important detail might have slipped through the chunks. For example, you might read a research paper, but your “εὕρηκα” moment might be completely different than mine. Personalized context, as extracted from agentic memory, should have an outsized influence in RAG architectures, as true learning is not objective but subjective. Yet mostly it doesn’t. There should be no need to relearn what you already know.
When building effective agentic Question/Answering solutions, retrieving fresh and accurate information from credible, likely proprietary, external information sources is a powerful enabler. But it is not without risk. If you do not have tight control over the quality of that data source, you need to validate every query. Otherwise, your reputation will be quickly derailed like Gemini’s infamous “how many pebbles should I eat per day” response.
But this validation comes at a cost.
So, how do you get the most value out of credible sources to improve the response of your agents ? Why do so many implementations get it wrong?
In its simplest form, RAG methods follow a one-round retrieval paradigm, where the user’s prompt is first embedded into a vector representation and matched against a vector-based index of document chunks stored in a knowledge base or other internal repository.
In general, RAG works around 5 steps.
User Prompt → Retrieval → Augmentation → Generation > Response.
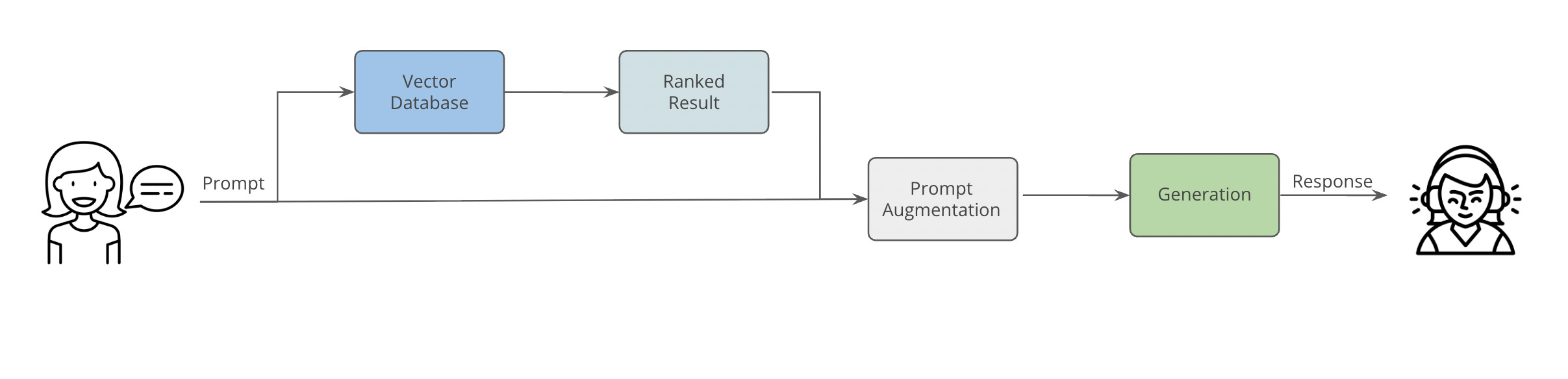
1. User Prompt
The process begins when, for example, a financial analyst asks a question in natural language, such as “What is the social sentiment around European bank earnings this week?”. The system then converts this question into a vector representation using an embedding model.
2. Retrieval
Next, the system searches the vector database to find information that is semantically closest to the prompt in vector representation. A similarity search returns the top-k documents, which might range from investor commentary on Deutsche Bank profits to concerns about Credit Suisse restructuring.
3. Augmentation
The retrieved posts are then injected into the original prompt to give the language model additional context. For example, the prompt now includes a handful of representative news articles alongside the analyst’s query.
4. Generation
The language model uses the augmented prompt to generate a summary or direct answer. In the example, it might respond with “Sentiment is cautiously positive: Deutsche Bank and BNP Paribas show strength, though concerns remain around Credit Suisse.” This step is usually where hallucinations occur, as the model may invent claims not present in the retrieved posts or oversimplify mixed signals into a single narrative.
5. Response
Finally, the system returns the generated answer, sometimes with citations to the retrieved posts for transparency.
The retriever then selects the top-ranked chunks based on vector similarity. These retrieved chunks are then used to augment the initial prompt and are provided to the model. Which then generates the response using both the retrieved evidence and the prompt. This is all good and dandy for most PoC/Demos, where data sources are simple and generation trumps engagement. The harsh reality is that basic RAG often struggles with QA tasks when the number and complexity of documents increase. Simple RAG methods typically use sparse-retrieval techniques to fetch documents based on keyword overlap. An example of sparse-retrieval is the BM25 algorithm, which returns a list of top-k documents based on relevancy.
Unfortunately, we have to observe, though, that the top-k strategy, which only takes the "k”-most relevant documents, frequently misses “golden chunks”, leading to incomplete or inaccurate answers. Golden chunks are ground-truth text passages containing the verified correct evidence needed to answer a query. Since these are used to evaluate retrieval quality in RAG systems, it’s obvious that this seemingly elegant approach is experiencing some problems.
Common problems
Most demo-level implementations fail when going into production environments for one or several reasons, since some of them are interrelated:
Context Window Saturation: If too many documents are included, early parts may get truncated; long retrieval contexts can also overwhelm the model’s capacity.
Feedback Loop Missing: The simple RAG shown above lacks a mechanism for internal self-checking to verify the consistency of the generated response.
Granularity Mismatch: If the granularity of retrieved chunks (paragraph vs sentence vs document) may not suit the reasoning step, it may cause loss of nuance or context.
Hallucinations: When the model generates information that is not supported by the retrieved documents or factual data. They typically arise from gaps in retrieval, misinterpretation of context, or the model’s tendency to “fill in” missing details.
Knowledge source disambiguation: You have several similar knowledge sources and don’t know which one is the right one.
Limited adaptability: Difficulty adjusting retrieval and reasoning to new domains, tasks, or changing knowledge sources.
Modality misalignment: If modalities are different, i.e., image and text embeddings are not in compatible vector spaces, then similarity scores, retrieval, or fusion across modalities will be misleading.
Noisy retrieval: Retrieval of irrelevant or low-quality text passages that dilute or obscure the correct evidence.
Query drift: where autonomous query reformulation by LRM drifts away from the original query and leads to less relevant results,
Retrieval laziness: where in the iterative agentic retrieving, the model prematurely terminates search due to context overload: specifically, the heavier the context retrieved from the previous round, the less likely the agent will initiate the next retrieval action due to “cognitive burden”. Such a cognitive burden is also observed in function calling.
Shallow reasoning: relies mainly on surface features, heuristics, or pattern-matching rather than deeper logical, causal, or structural understanding. It often yields fast but brittle or superficial conclusions that fail under novelty or when reasoning beyond the obvious. Or, in other words, reliance on surface-level associations rather than deeper logical or multi-step connections when generating answers.
Single-hop vs Multi-hop: Whether the model can generate an answer using one directly retrieved piece of evidence (single-hop) or must reason across and combine multiple pieces of evidence from different sources (multi-hop).
And this adds to the already well-known problems of intent detection and data quality. Without precise, well-structured data, even the most powerful models can produce misleading and/or irrelevant outputs. As I had mentioned before, context engineering should play a pivotal role in your strategy to guide how your agents interpret and utilize data. Yet, even though the list of concerns is long, there is no reason to stop implementing RAG.
Here are some ideas, based on recently published research papers, that provide closure to some, maybe all of these problems.
Solution approaches
Most of the problems can be grouped into retrieval-level issues, reasoning / generation-level issues, control / agentic / interaction-level issues, and system-level / external issues. But let’s start with some basic ideas to improve RAG performance.
Dense Semantic Matching
Dense semantic matching represents both queries and documents as dense vectors, typically using embeddings generated by models like Facebook’s Dense Passage Retrieval (DPR). This approach aims to capture the semantic meaning of the text, rather than exact keyword matches. This leads to more contextually diverse information being provided to your agent.
Re-ranking
Re-ranking is a two-step process where an initial set of documents is retrieved using a standard method (like BM25), and then, in a second step, a more sophisticated model re-ranks these documents based on their relevance to the prompt.
Multi-hop Querying
Multi-hop querying involves retrieving and reasoning over multiple pieces of evidence to answer complex questions that cannot be answered by a single document, each time building upon the information gathered in previous hops. This is especially helpful if you have more than one overlapping data source.
Knowledge Graphs and Symbolic Reasoning
Knowledge graphs provide a framework for representing relationships and entities, facilitating logical reasoning and inference. Symbolic reasoning over these relationships enhances the ability to perform tasks that require understanding of abstract concepts, causal relationships, and structured information.
One-SHOT Strategy — “Casting a Bigger Net”
This strategy aims to fix a problem during retrieval, where instead of a fixed top-k retrieval, this approach uses a token-constrained retrieval strategy. The bottleneck for retrieval is often the context window. The solution here is to retrieve as many chunks as possible that fit within the token budget (e.g., 32k tokens).
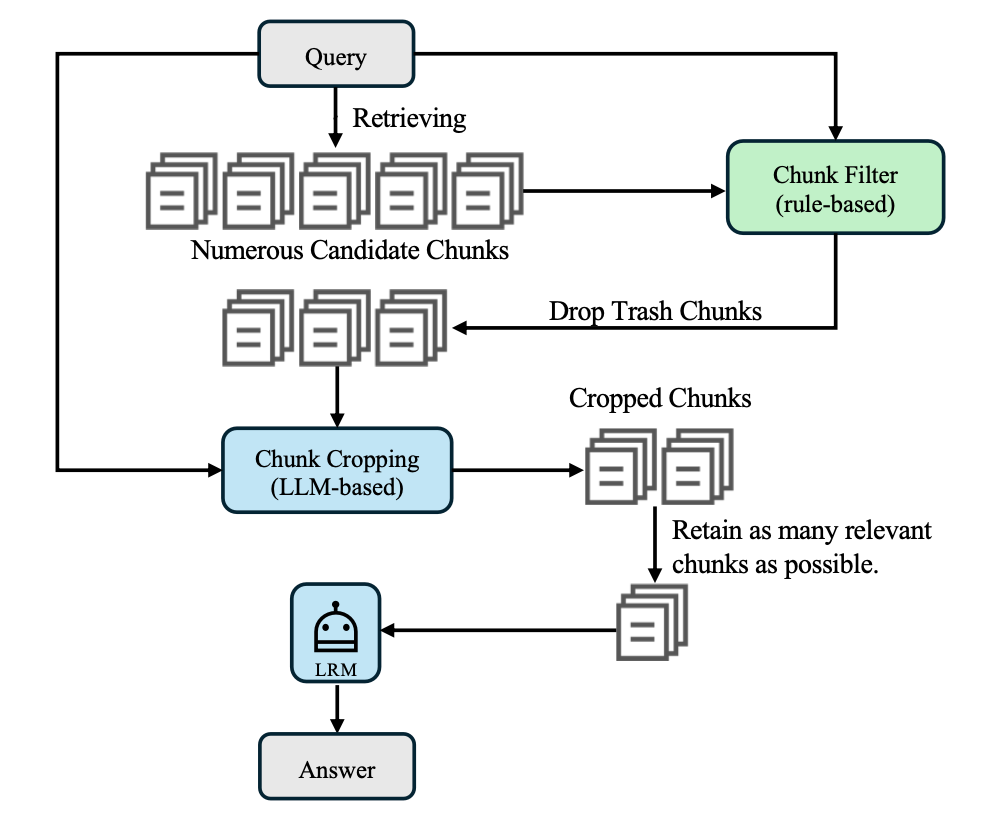
Then we rank chunks by relevance per token to maximize evidence density. We apply a chunk filter (rule-based, e.g., by metadata like date/location) to drop irrelevant chunks and add missing ones. And finally, we crop the chunks to shorten them and remove redundant information. In theory, this should greatly increase recall, ensuring more golden chunks are included in one retrieval pass, while still controlling input size. I am not a fan of saturating the context window because it might still confuse the attention heads and might lead to primacy/recency bias and the well-known lost-in-the-middle problem.
Iterative Strategy — “Casting a Small Net Multi-Times”
This proposed solution targets the reasoning state where the agent needs to decide if more retrieval is needed. What I love about this approach is that it is an Agentic RAG framework where the agent actively reasons over retrieval quality in multiple turns, retrieves more data, reformulates queries, and issues tool calls when needed.
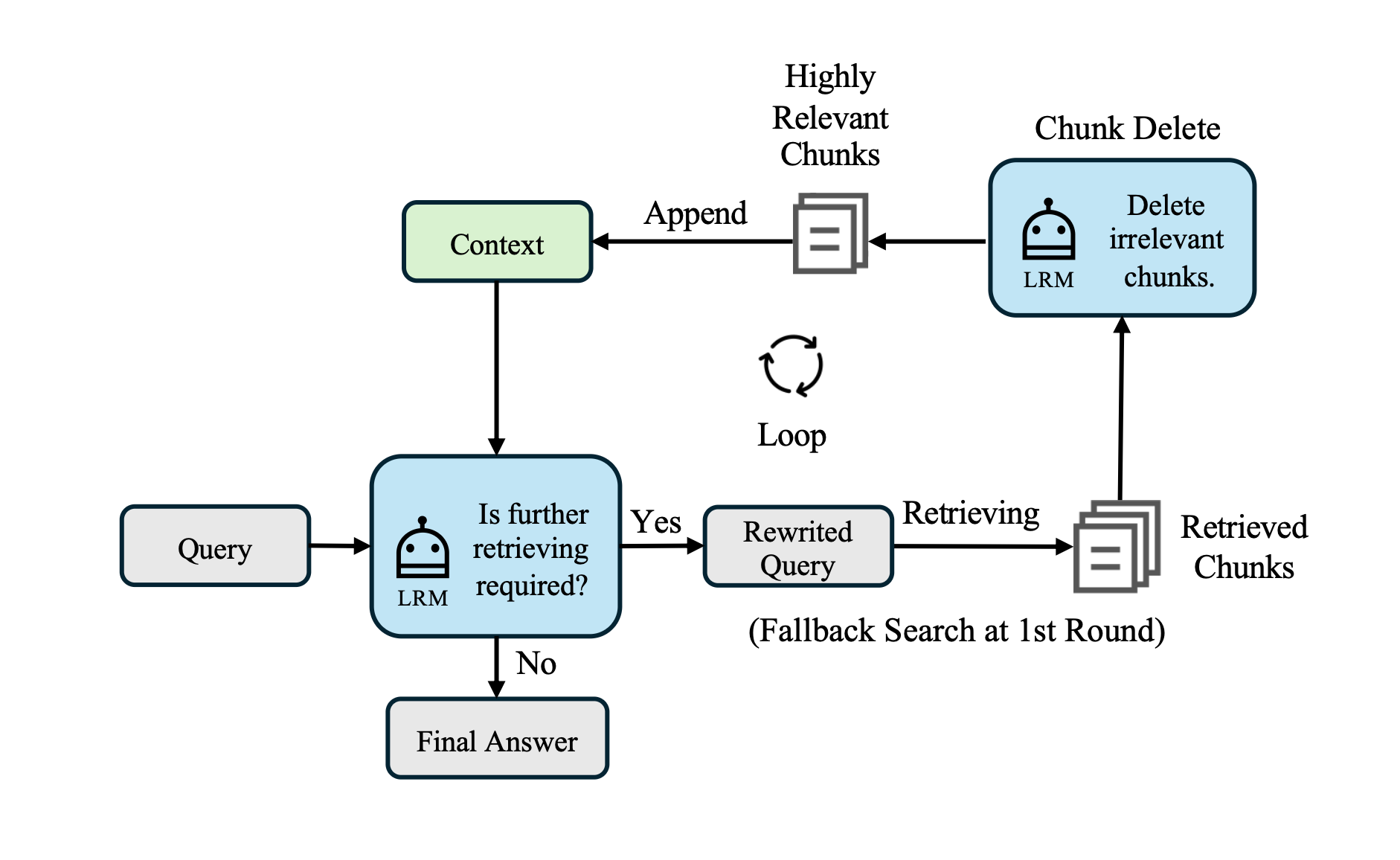
While this adds more cost and complexity to the RAG process, it also improves quality by integrating newly retrieved chunks into context and can continue searching with the new information. One note of caution. If there is no validation on reformulation, then this approach might introduce query drift (when reformulation strays from intent). Also, the chunk delete function allows the model to remove irrelevant information from context to solve retrieval laziness (when a heavy context makes the agent stop searching prematurely). While, in general, I like the reformulation approach, the solution might loop and reformulate ineffectively many times, wasting resources.
Multi-Turn Retrieval Process
Of course, the naive solution to that would have the iterative retrieval process operate within a maximum turn limit (typically set to a finite number of turns) to balance thoroughness with efficiency.
But I think we can do better.
Let’s assume in each turn, the agent performs the following acts:
Reasoning Phase: The agent analyzes the current context, including the original query and all previously retrieved information, to assess whether further retrieval is necessary.
Abort Evaluation: Before formulating a new query, the agent evaluates whether sufficient information has already been gathered to answer the query. If the information is deemed adequate, the agent can choose to abort further retrieval and proceed to generate the final response.
Query Formulation: If additional retrieval is necessary, the agent generates a focused search query designed to address specific information gaps identified during reasoning.
Context Integration: Retrieved chunks are only integrated into context if they add knowledge, providing the agent with additional information for subsequent reasoning.
Iteration Decision: The agent determines whether to continue searching for more information or provide a final answer based on the accumulated context and retrieval results.
While this solution sounds like a fun thing to do, it also adds a lot of non-deterministic improvements, which, in case something goes wrong, can multiply the problem. Do we have to execute all of this overhead for every prompt?
What if it’s just something really simple?
Multi-Agent Orchestration for Adaptive Retrieval-Augmented Generation
MAO-ARAG (Multi-Agent Orchestration for Adaptive Retrieval-Augmented Generation) is a framework that tries to solve this control problem by dynamically adapting RAG workflows to match the complexity of different queries.
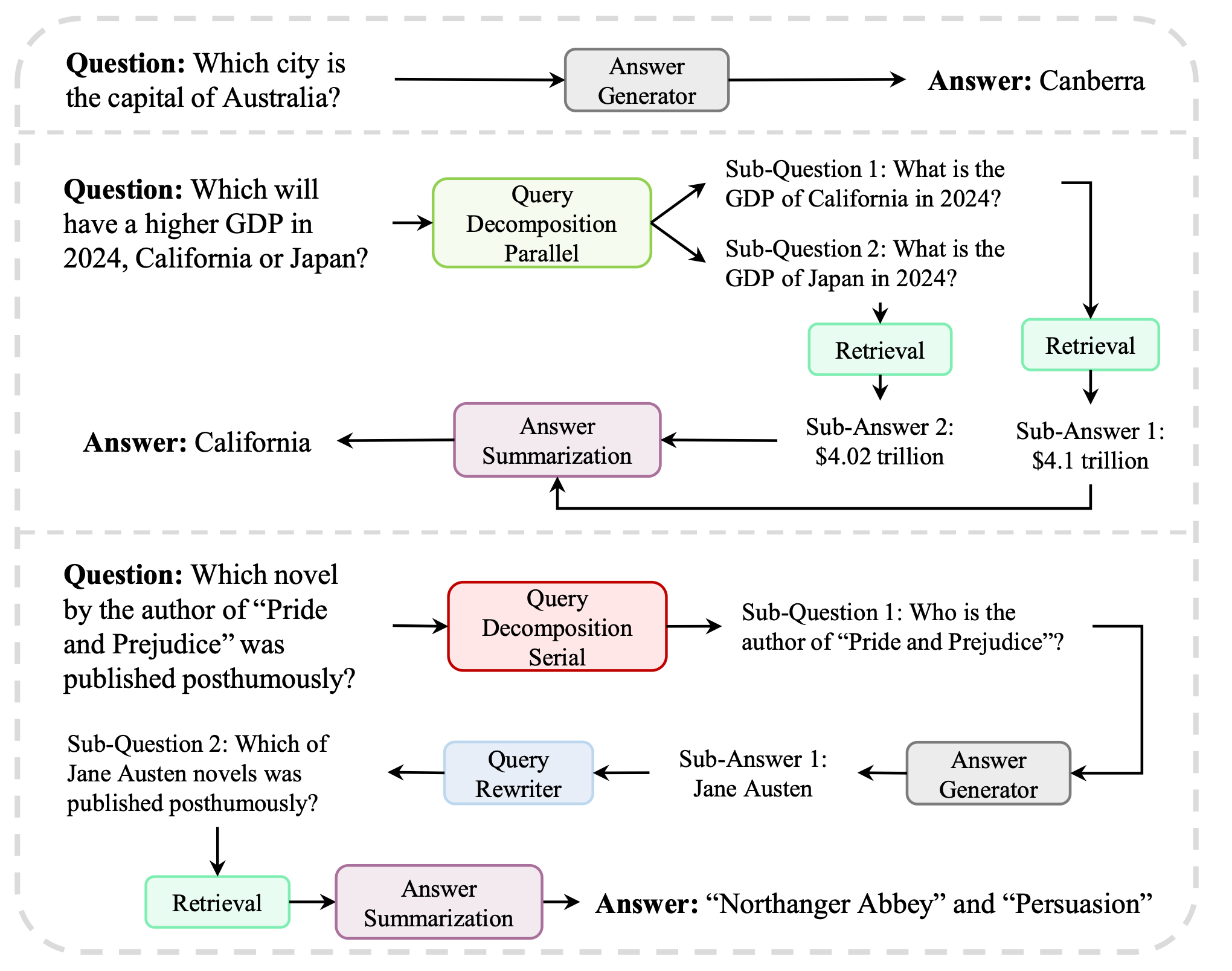
The research team models their RAG solution as a Multiagent Semi-Markov Decision Process (MSMDP), which effectively captures coordination among agents with distinct roles.
What I like about MAO-ARAG's core architecture is that it is built upon a central planner agent that orchestrates several worker agents to operate RAG workflows.
Similar to my soon to be launched Postwriter agent, MAO-ARAG’s planner agent decides how to process incoming queries by selecting and coordinating executor agents, such as Query Decomposition Serial (QDS) for sequential sub-question breakdown, Query Decomposition Parallel (QDP) for independent parallel processing, Query Rewriter (QR) for question reformulation, Document Selector (DS) for filtering retrieved content, Retrieval Agent (RA) for external knowledge search, Answer Generator (AG) for response production, and Answer Summarization (AS) for synthesizing results from multiple sub-questions, adapting the workflow from simple single-agent tasks to complex multi-turn, sequential or parallel operations based on query complexity.
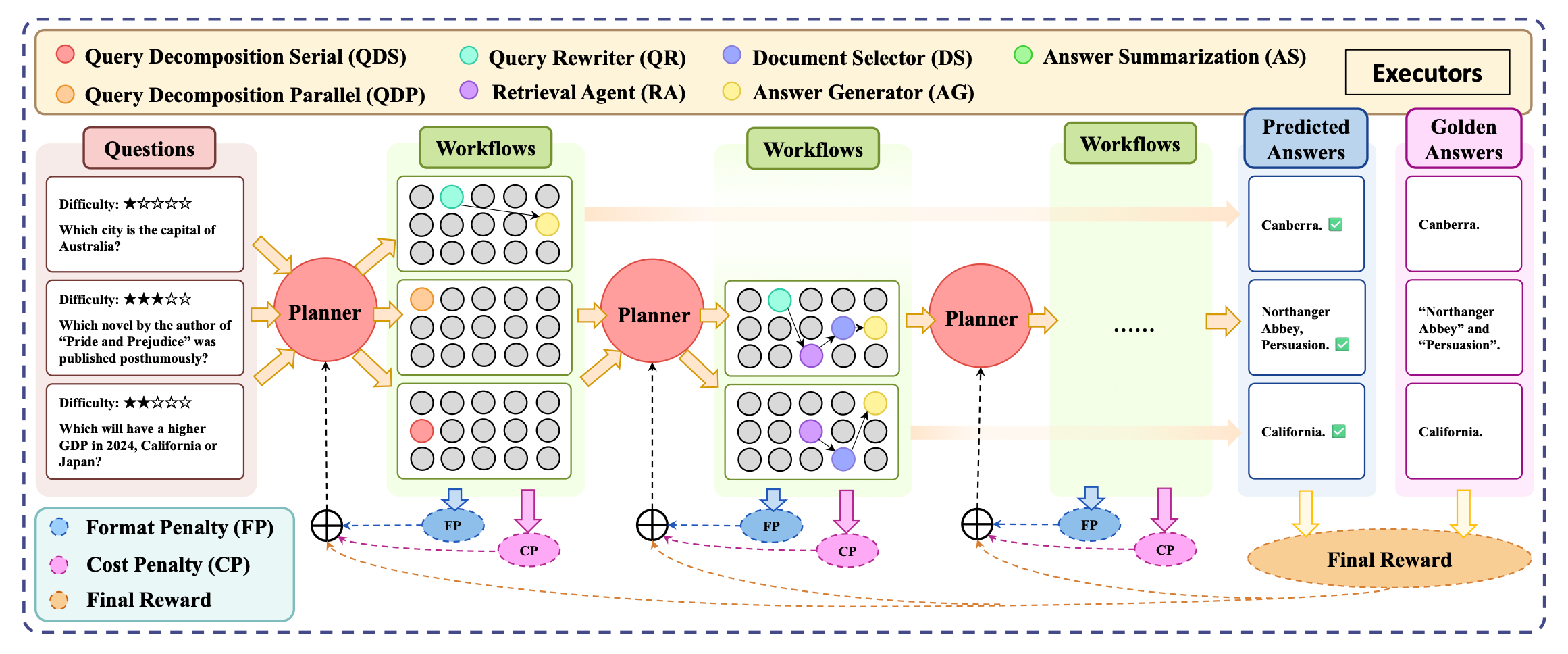
The control benefits of this solution are, besides being highly modular, in MSMDP, the duration of an action is not fixed, allowing for effective coordination across different time scales and agent roles, making it an adaptive RAG. And that is actually quite neat. Being able to adapt to the problem size.
Where the planner agent:
Analyzes the question complexity and information needs
Selects appropriate executor agents
Orchestrates them into a multi-turn workflow
Adapts the workflow dynamically based on intermediate results
If that works, it could be groundbreaking. However, I also believe it would fail in production environments as knowledge routing can be highly complex as well.
DeepSieve Information sieving via LLM-as-a-knowledge-router.
This is what DeepSieve is trying to address. DeepSieve starts by breaking down queries into structured sub-queries and recursively routes each to the most appropriate knowledge source, filtering out irrelevant information through a multi-stage information sieving process.
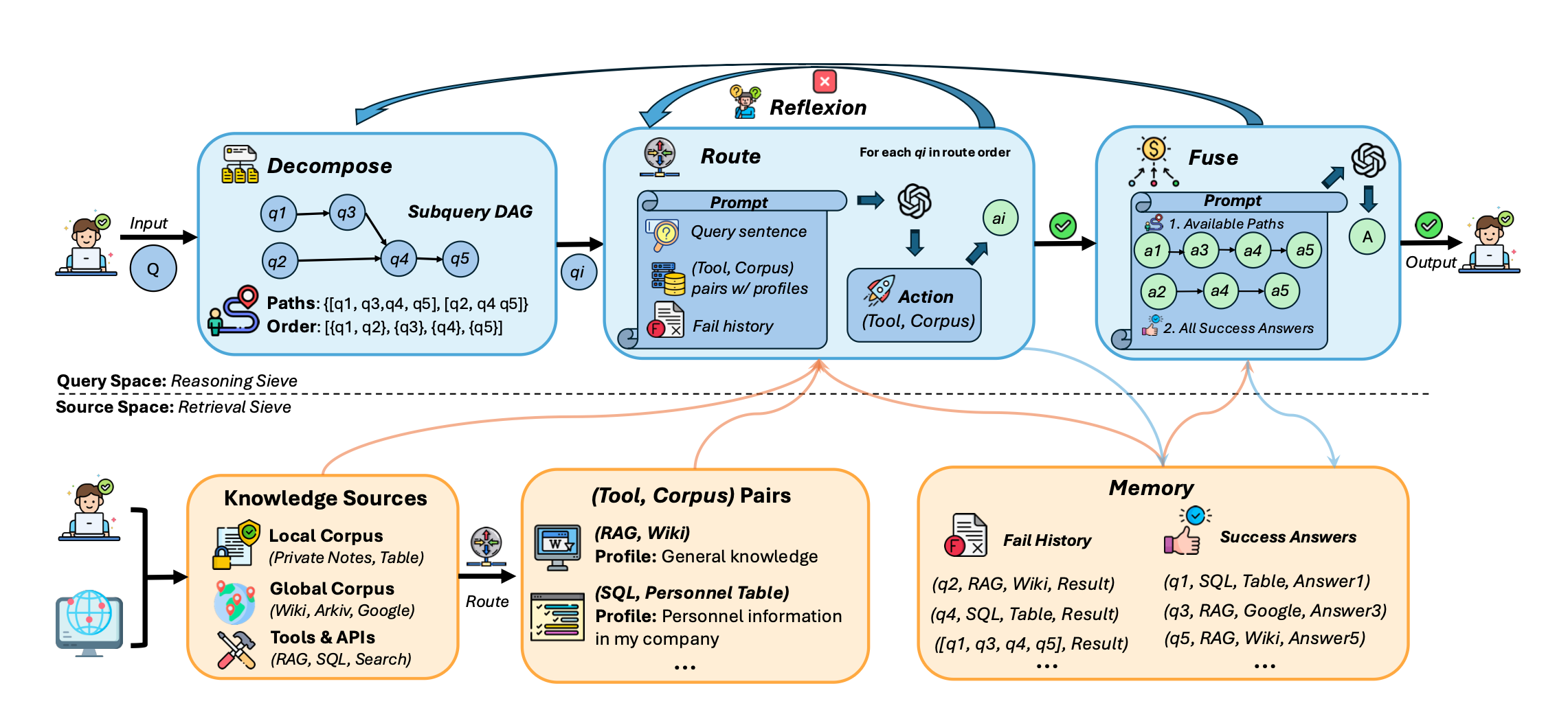
How does it work?
Multi-Stage Information Sieving: DeepSieve starts by decomposing complex queries, routing sub-questions to appropriate knowledge sources, and iteratively refining answers through reflection and fusion.
Decomposition and Routing: The identified sub-questions are routedto the most suitable knowledge source, such as structured databases or unstructured corpora.
Iterative Refinement: Answers are handed over to a reflection mechanism that allows for the iterative refinement of answers, controlling the accuracy and depth of reasoning over multiple hops.
Fusion of Answers: The agent fuses partial answers from various sources, synthesizing them into a (hopefully) coherent final response.
What I like about DeepSieve is that it works with a variety of source types (e.g., API, SQL, RAG corpus) and can generate a corresponding action plan based on the knowledge received. This source-aware routing could be highly valuable for the efficient management when using agents as controllers.
Benchmarks
Now that we’ve discussed various challenges and potential solutions in question answering agents, we are still lacking tools to evaluate and benchmark our approaches.
Here are some that might be helpful:
Natural Questions (NQ)
Natural Questions is an open-domain question answering dataset developed by Google Research, comprising over 300,000 real user queries sourced from Google Search logs. Each question is paired with a Wikipedia article that contains the answer, along with a long answer (typically a paragraph) and a short answer (usually a single entity or phrase).
“question_text”: “who founded google”,
“question_tokens”: [”who”, “founded”, “google”],
“document_url”: “http://www.wikipedia.org/Google”,
“document_html”: “<html><body><h1>Google</h1><p>Google was founded in 1998 by ...”This dataset is designed to evaluate models’ abilities to read and comprehend entire documents, making it a great resource for assessing both retrieval and generation components in QA systems.
HotpotQA (web)
HotpotQA is a multi-hop question answering dataset consisting of 113,000 Wikipedia-based question-answer pairs. Based on this 2018 paper, the questions in the dataset allow reasoning over multiple supporting documents to answer, making it particularly useful for testing retrieval-augmented generation (RAG) pipelines.
Here is an example:

HotpotQA provides sentence-level supporting facts, enabling models to perform more explainable reasoning by grounding their answers in specific pieces of evidence. This is important because it allows agents not only to generate the correct answer but also to justify that answer with explicit evidence.
MS MARCO (Microsoft GitHub)
I might look like a Microsoft fanboy by now, but I am not. MS MARCO (Microsoft MAchine Reading COmprehension) is a large-scale dataset focused on machine reading comprehension and passage retrieval. MARCO includes over 1 million real user queries sourced from Bing search logs, each paired with relevant passages extracted from web documents. The dataset is primarily used to evaluate the retriever component of RAG systems, providing a benchmark for assessing models’ abilities to rank and retrieve relevant passages efficiently.
In closing
When you are building your agents, incorporating high-quality real-life data will be a make-or-break characteristic. I hope some of the problem statements have inspired you to find better solutions than the one I have presented in this post. I am personally very excited about Agentic RAG because it introduces reasoning and tool use into retrieval, enabling more adaptive behavior. This recent progress has moved beyond static, rule-based pipelines toward more actionaly, dynamic, decision-driven agents, and I am all for it. Agentic RAG could represent a paradigm shift for AI agents that actively reason over retrieved information, dynamically refining their queries, sourcing new information, and interpretations in real-time. At least for me, I will refine my DeepCQ agent with some of these ideas.
However, all of this assumes that “relevance” is the KPI to optimize. Maybe it’s not.
I hope you found this post worth your time. Please like, share, and subscribe.
Helps me a lot to grow this Susbtack.
Sources
Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLMs (arxiv)
Fishing for Answers: Exploring One-shot vs. Iterative Retrieval Strategies for Retrieval Augmented Generation (arxiv)
MAO-ARAG: Multi-Agent Orchestration for Adaptive Retrieval-Augmented
Generation (arxiv)
DeepSieve: Information Sieving via LLM-as-a-Knowledge-Router (arxiv)
Agentic RAG with Knowledge Graphs for Complex Multi-Hop Reasoning in Real-World Applications (arxiv)
