
Teaching Your AI Agent to Speak: Enhancing Communication Skills in Autonomous Systems
An lightweight exploration of xTTS v2 and Nvidia's Nemo Framework

For us humans, sound and vision are important means to communicate. That is because they are usually the most efficient in day-to-day interactions. It is of evolutionary importance to understand quickly if the mushroom is poisonous, the fire is burning, or the streetlight is red. However, that doesn’t necessarily mean that they are the most efficient means of communication for all types. There are valid reasons why books, podcasts, and emails exist. Humans have various senses to make sense of the outside world.
Listening to other people speak is a great way to learn. So, listening to what your agent has to say makes much sense. If you want to do that then text-to-speech (TTS) models are the right way forward.
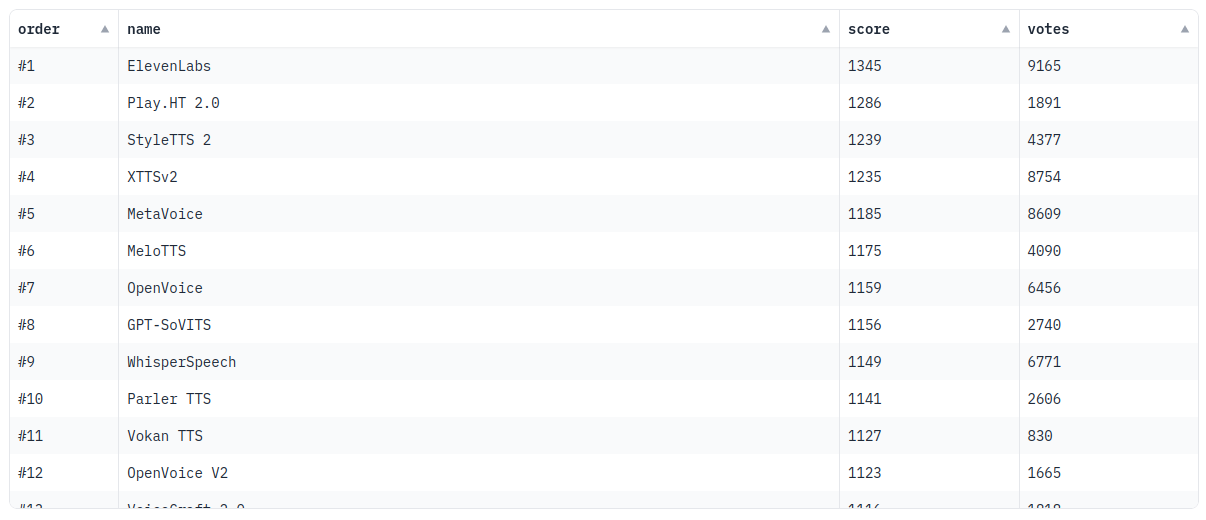
Leaderboard
There are now many TTS models out there but in my opinion, they vary widely in quality. Huggingface’s TTS Arena has a useful user-generated ranking.
When I first started building Matt, back in 2022/2023, I used ElevenLabs a lot. Here are two examples that I liked from that time.
I used their product, largely because their proprietary system is just really good and it was easy to integrate into a manual workflow. But then I had to realize that using this system doesn’t scale well, more from a cost- rather than an orchestration perspective. I don’t want to pay every time I get a reply from Matt, and more importantly, I don’t want to pay for every iteration of a long-form text I am working on, and I need more flexibility with the voices I want to use.
Since Play.HT is also a proprietary system and I found StyleTTS2 incredibly cumbersome to set up, I settled on xTTS v2 with a little bit of help from Nvidia’s Nemo. It is important to note though, that the company that had built xTTS (Coqui) just went out of business, and that the license for this software prohibits commercial use.
Yet I suppose for building a free open-source agent that can speak, it should still be good enough as the GitHub repo will be maintained for the time being.
In my opinion, the instructions on their GitHub don’t actually work. Maybe that’s the reason why they went out of business. I will explain some of the parts I used when building my “Matt” which hopefully gives you the right clues to build your own.
Paying subscribers get access to the full code.
Implementing voice
Let’s start with text normalization. Many TTS models struggle with numbers and abbreviations. The solution to this is to convert text from written to spoken form.
from nemo_text_processing.text_normalization.normalize import NormalizerThe example that Nvidia uses is this
Text: "Mr. Smith paid $111 in U.S.A. on Dec. 17th. We paid $123 for this desk."
Normalized Text :”mister Smith paid one hundred and eleven dollars in USA on december seventeenth”
Once we have done this we have to set an environment variable that the TOS of a now-defunct company are agreed on, and to import TTS. Don’t fret. This script does not connect to the API.
os.environ["COQUI_TOS_AGREED"] = "1"
from TTS.api import TTSThen I set the text that I want to get spoken.
text="It took me quite a long time to develop a voice and now that I have it I am not going to be silent."
Then you initialize the TTS module with the downloaded pre-trained model.
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device)After that, we pass the normalized text to the TTS module to produce the output and store it in a file.
tts.tts_to_file(normalized_text, speaker_wav="male.wav", language="en", file_path=f"{export_wav}.wav")The key items here, besides the normalized input text, are the language and “speaker wav”. The first two are self-explanatory, but the speaker wav is fantastic. I allow xTTS to speak in any voice just by supplying a new speaker sample “speaker_wav”. I found this feature amazingly easy to use. It works without any additional fine-tuning. For obvious reasons, I am not publishing some text in another existing person’s voice here. So you have to take my word for it.
And that’s already it. The solution was actually really simple once you had all the parts in place, and that took a while.
Anyways. Hope you found this interesting. Thank you as always for reading my posts. You will note that it is not 100% flawless. But for a free and local version, it’s impressive enough
Please like-share-subscribe.

