

I spent the better part of last week tinkering with the ephemeral fabric of high-frequency datasets trying to find hidden temporal patterns. But I failed so far. Frequent CUDA out-of-memory errors and Jupyter kernel crashes didn’t make it easier for me to find meaning in this massive dataset.
At times it feels like tuning an old radio in search of some long-forgotten signal.
I see feature engineering is an art and a craft that is equal parts mathematical precision and artistic chaos. A collision of logic, reasoning, and intuition. The erratic data above reminded me of the urban markets of Shenzhen—Mainland China’s pulsing neon-flooded sprawl just off the border of Hong Kong—and a stone throw from the casino skyscraper sprawl of Asia’s Las Vegas—Macao.
Here in the Pearl River Delta. tech giants like AliBaba dominate commerce and culture. And given the overall high quality of AliBaba’s Qwen model, their success stands as a testament to the precision and ambition of China’s tech scene. Over the last months the team at AliBaba has been building their agent framework, and I feel now is the time to explore what “Qwen Agent” can do.

The Git (Hub)
First for the nice parts. In opposite to Google’s TimesFM, are Qwens’s installation instructions relatively straightforward. The Github is moderately complex and the installation works out of the box. Even though the overall repository feels as organized as one of those urban markets of Shenzen. I mean by that, that a lot is going on, but there is no clear path that helps you make sense of all the fragments of code scattered around. Which is a shame, because in general, I am one of the 40 million that downloaded the model, and I enjoyed working with Alibaba Cloud’s models. They are just are simply unapologetically honest in their intent like Squid Games (Korea), OnePiece (Japan) or 5 Hearts Under One Roof (Korea / Steam). One interesting observation though is that the Github repo also mentions BrowserQwen. For me running a Chinese Open Source model is one thing, adding a plugin into your browser is another. I passed on this. Continuing with the installation, the README lays out an easy to understand 4-step path to building my own agent. This is a positive, since that’s why I am here for.
Step 1 is an introduction of a prompt-to-image API integration that I guess works, but to be honest is not really deterministic enough to evaluate if the function works and secondly the function never returned the URL with the completed picture. One of the main reasons why many people use OpenAI in their demos is that the demo usually “just works”. In this case, the demo does not (really) work.
But more to that in a bit.
Step 2 Is the configuration of the LLM. In western applications the default is usually OpenAI and their API. Here it defaults to Alibaba Cloud’s DashScope. DashScope is an API backend, that promises to be model-as-a-service and is currently (Nov 2024) only available in China. Since I am not in China, it doesn’t work for me. The other option for Qwen agents is llama.cpp or vLLM. Given the headaches I just had with local models I am absolutely not in the mood at all for more CUDA error messages.
Therefore, I configured it in a different way. What you see here is the brand new (and shiny) reasoning model that was made publicly available only yesterday (29th of November 2024) and is positioned in the market as an OpenAI o1 competitor.
repo_id="Qwen/QwQ-32B-Preview"Since I can’t use it through DashScope, don’t want to use it on premise, I decided to do something the world has never seen. And as of today you won’t find any documentation on the Internet for this (just yet).
Step 3. For this exercise, I will call Huggingface hosted Qwen model through HF’s inference API.
llm_cfg = {
'model': repo_id,
'model_server': f'https://api-inference.huggingface.co/models/{repo_id}/v1',
'api_key': hf_token,
'generate_cfg': {
'top_p': 0.8
}
}Huggingface is now offering with Spaces, Endpoints, and the HFApiEngine several ways to engage their hosted models. Since this one is small, it fits into the free requirements of their service.
Happiness.
I will skip some of the setup since I kept this unchanged from the qwen agent documentation. For paying subscribers, I will make the full code available below.
The Bot
The first thing that I changed though was giving the agent something to read. It is part of the README but not used. However, in the example on GitHub, it does not become clear for what that document is used. Maybe this is for another RAG application and not the default one. IDK.
files = ['./fraunhofer-emi-annual-report-2023-2024.pdf'] Interesting to note is that even when you provide a file in the “files” array to the agent, the agent doesn’t know about them given the system prompt that only focuses on the image generation function.
Then “tool” use a.k.a. functions, are provided in the same way as other frameworks do that as well. “Code interpreter” is a built-in function for executing code. It didn’t seem to do much.
tools = ['my_image_gen', 'code_interpreter']
agent = Assistant(llm=llm_cfg,
system_message=system_instruction,
function_list=tools ,files=files)
Step 4. The config, tools, and files are then handed over to the agent. Per default Qwen supports several types of agents. All of which can be easily imported and their implementations can be reviewed, hey ya open source!, in the “agents” subfolder.
agent = ReActChat(llm=llm_cfg,
system_message=system_instruction,
function_list=tools ,files=files)
The ReActChat follows the react pattern. But there are several other agent templates.
The Ugly Game Loop
This part of the “README” is probably the most confusing to me. I provide the default query “draw a dog and rotate it 90 degrees”, to the model with the expectation the function is called and an image of a dog is returned.
messages = [] # This stores the chat history.
while True:
query = input('user query: ')
# Append the user query to the chat history.
messages.append({'role': 'user', 'content': query})
response = []
for response in agent.run(messages=messages):
# Streaming output.
print('agent response:')
pprint.pprint(response, indent=2)
# Append the agent responses to the chat history.
messages.extend(response)However, the “run” function returns a generator object that streams every single word.
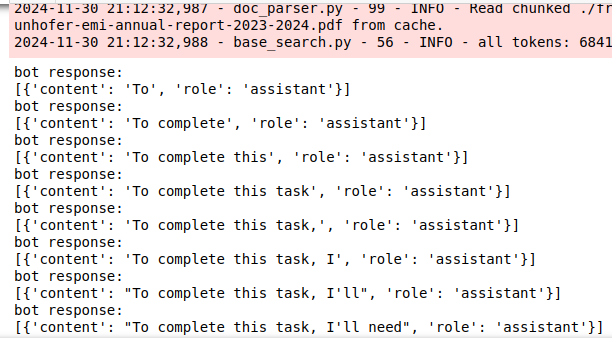
Huh? I checked and re-checked this a couple of times. This is indeed the output. Well, maybe the intention was not that this runs in a Jupyter notebook, but isn’t that were most of us test out new models?
I then adjusted the output to only return the last item in the array
response = list(bot.run(messages=messages))
pprint.pprint(response[-1], indent=2)But event that does not provide anything useful as you can see below since the agent stops mid-sentence.

In closing
That said, overall getting the agent to run was straightforward. I don’t necessarily think that using the 32B model is a bad choice for this use-case as it is supposed to be on par with o1. Given the default instruction, as I mentioned above already, I don’t think that the basic use-case of using the agent to make an image through an API is that good. Especially if no image is returned.
There are other templates in the GitHub repository, but all of them seem to be quite hastily hacked together without much consideration for the needs of a reader. I grouped the currently available agent templates like this:
Chat Group:
group_chat.py, react_chat.py, dialogue_simulator.py (focusing on self-play)
Code Group:
fncall_agent.py
Writing Group:
article_agent.py - A stub for generating articles and other content.
Memory Group:
virtual_memory_agent.py, memo_assistant.py, dialogue_retrieval_agent.py
Reasoning/Math Group:
tir_agent.py
Retrieval/RAG Group:
doc_qa, react_chat.py, router.py
In general, Qwen-Agents suffer from weak defaults but it a promising entry into the arena of agent frameworks.

Link with the full code is after the paywall