
Towards a Large Time Series Model
Transformers for Financial Time Series Forecasting

Working with a proprietary dataset from a leading investment bank, my team and I had the unique opportunity to perform an interesting exercise in financial modeling. This analysis is based on a random sample of 1 million rows, 39 financial instruments, 10 responders, and 79 features extracted from the dataset and offered us a real-world challenge to test the power of Transformer Models for time series forecasting. It was the perfect environment to hypothesize what a Large Time Series Model might be capable of uncovering in search of deep insights and delivering actionable predictions in financial markets. Large Time Series Models aim to achieve this by tackling key challenges in time series forecasting, such as capturing long-range dependencies critical for understanding extended temporal patterns, ensuring scalability to handle large datasets and multiple time series, and offering generality as a foundation model that can be fine-tuned for specific tasks.
Histograms
Exploratory Data Analysis (EDA) was our first step in understanding the dataset’s intricacies. Visualizing the data provided invaluable context. A matrix of histograms revealed the distributions of individual features, highlighting potential outliers and skewed data. One of the challenges in building accurate predictors is missing data and outliers. Therefore, a thorough data preprocessing phase is ultimately crucial for maintaining data integrity. Missing values, which are common in stock data due to non-trading days or incomplete records, can be handled using strategies such as filling gaps with the average values of surrounding time stamps.

A few notable observations.
Features 18, 19, 20, 27, 28, 32, 33, 42, 43 show relatively symmetric, bell-shaped curves.
Features like 9, 10, 11 show multiple peaks, This could indicate distinct groups or categories within the feature.
Features 5, 6, 7, 8, 30, 31, 37, 38, and others show most values concentrated in a single bin potentially indicating encoded categorical data or highly consistent measurements.
Responder_0 through responder_8 are more concentrated around specific values indicating classification outcomes or categorical responses.
Some features (71, 72, 74, 76, 77) showed having large scale differences suggesting the need for normalization in any subsequent analysis.
Correlation heatmap
A correlation heatmap provides a visual matrix showing the strength and direction of relationships between variables in the dataset. This helps to identify patterns and dependencies in complex datasets, making it an effective tool for feature selection and dimensionality reduction. The heatmap of correlations we had generated provided another layer of insight, showing us which features moved in tandem and which are independent.
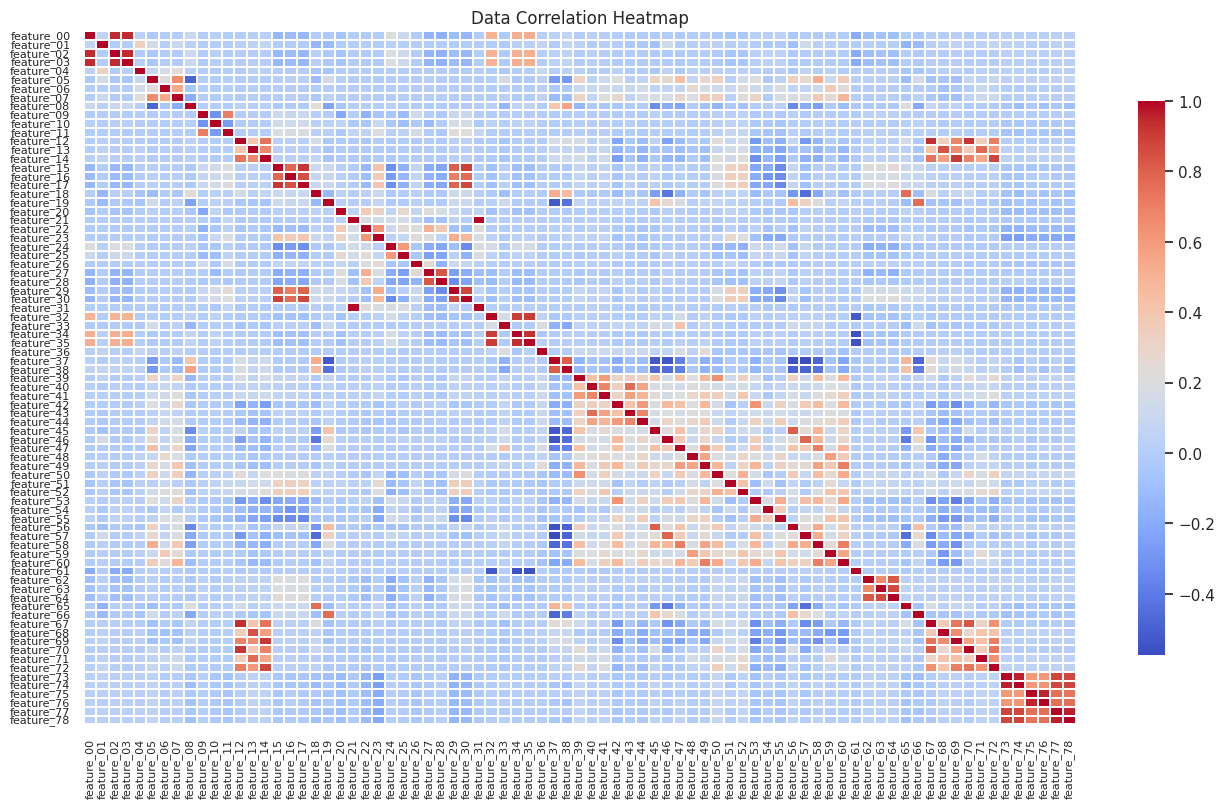
Looking at this correlation heatmap, there are several notable clusters
Early Features (0-4):
There's a distinct cluster in the top-left corner showing strong positive correlations (dark red) among the first few features. This suggests these features might be capturing related information.
Mid-Range Features (around 15-17):
There appears to be a small cluster of moderate positively correlated features in this range.
Late Features (72-78):
A very prominent cluster appears in the bottom-right corner showing a strong positive correlation with each other. This could indicate redundant information in these features.
Scattered Mini-Clusters:
Throughout the matrix, there are occasional 2x2 or 3x3 blocks of correlation. These smaller clusters might indicate localized relationships between specific feature groups
The majority of the heatmap shows light blue or white colors, indicating weak or no correlation between most features. This suggests that many of the features are capturing independent information, which is generally good for modeling purposes.
Time Series of Financial Instruments
As mentioned in the introduction, the dataset also includes information on which financial instrument is underlying the collected time series. Even though we are not permitted to share which instrument it is, plotting a time series for a given feature and for each symbol helps to observe trends, periodic patterns, and anomalies that could support both feature engineering and modeling strategies. We selected feature 25 because it had an interesting skewed histogram.
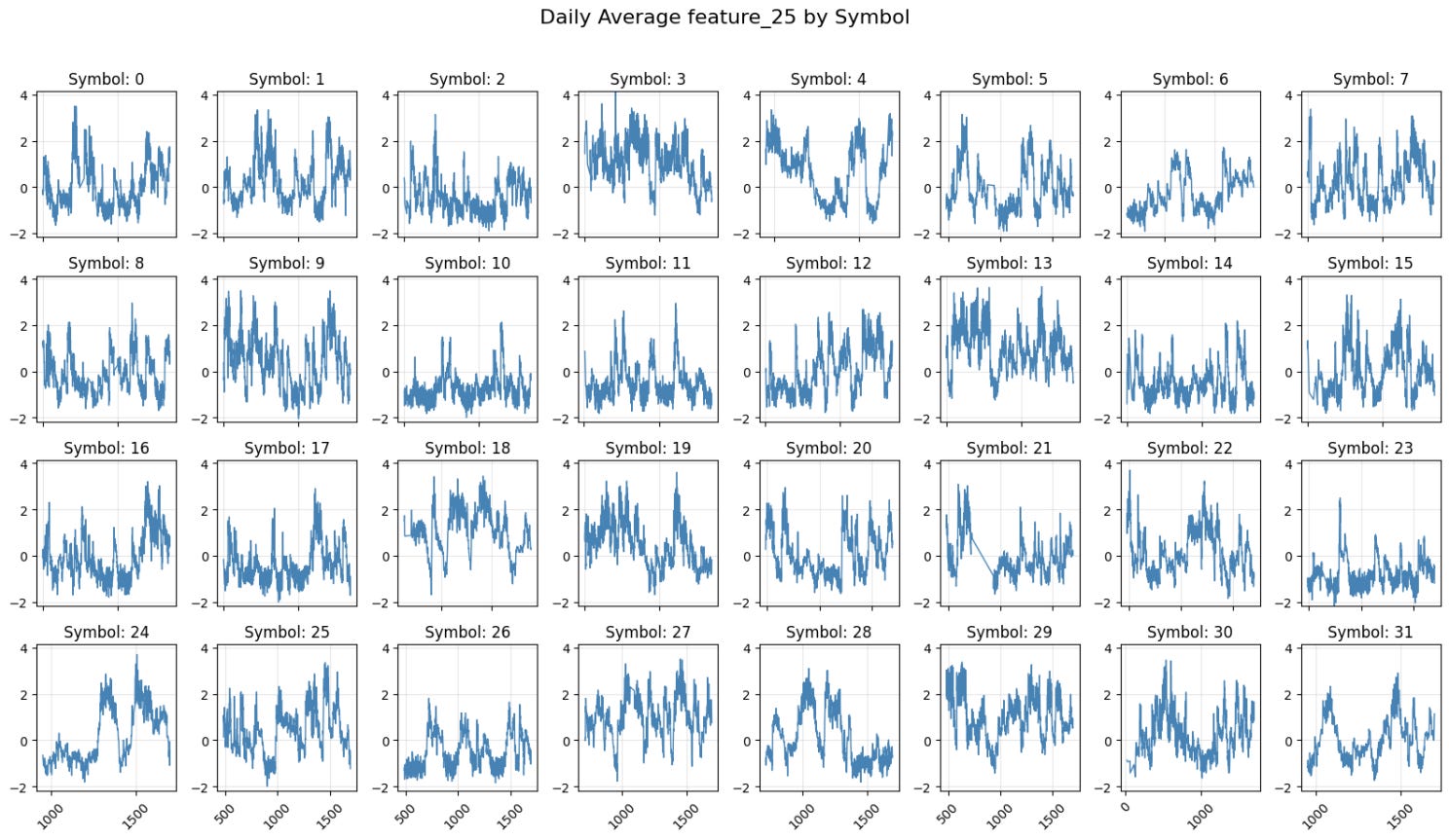
In order to get a meaningful comparison, we have standardized the scale providing a few notable observations.
Volatility Patterns:
Some symbols (like 9, 12, 13) show higher volatility with frequent large spikes, while others (like 10, 11) show more subdued movements. Symbol 23 appears to have relatively lower volatility compared to others
Trend Behaviors:
Some symbols show clear trending periods (like Symbol 16's upward trend near the end). Also, many symbols exhibit mean-reverting behavior, oscillating around zero.
Clustering:
Some symbols seem to share similar patterns, suggesting a possible correlation. For example, symbols 12-15 show somewhat similar volatility patterns. This might indicate these symbols react to similar market factors.
Data Quality:
The data appears continuous with no major gaps. All symbols have data for the same time period.
Seasonality Decomposition
Our analysis continues with Seasonality Decomposition using STL (Seasonal and Trend decomposition using Loess). This data science technique breaks a time series into three components: trend, seasonality, and residuals. However, since the data supplied for this exercise was not timestamp based, but ordinarily sorted thus providing a chronological structure to the data, the STL decomposition method could not automatically infer the frequency of your time series data. Therefore, we deployed a rolling window decomposition.

For none of the feature/symbol combinations, we could observe over the window period signs of seasonality.
A true sign of seasonality would typically show:
More regular, periodic oscillations
A consistent pattern that repeats at fixed intervals
Sustained increase in amplitude of these regular patterns
What we see instead looks more like:
A few isolated larger spikes
Irregular fluctuations
No clear repeating pattern
This does give bearing to our assumption that the dataset is a quite short-term dataset maybe from high-frequency trading. For the reduction of doubt, HFT can also experience seasonality effects in the form of :
Opening and Closing Effects: Volatility and liquidity often peak at market opening and close due to the influx of orders and news digestion.
Midday Lull: Activity tends to drop during midday as traders step away or wait for more data.
Volume Spikes: Certain times of the day, like economic announcements or earnings reports, can show predictable volume increases.
We gained some valuable insights into the temporal dynamics of the dataset, laying a solid foundation for forecasting. However, there in order to understand the time series further we have to measure similarity and group features and time series with similar behaviors. between series, even if they were slightly misaligned in time.
Clustering and Dimensionality Reduction
Dynamic Time Warping (DTW) is a technique that enables us to measure this similarity between series. In this step, we are specifically looking for features that exhibit comparable trends or seasonality patterns that can be clustered using k-means and similar hierarchical algorithms.
Reducing the dataset’s complexity was critical to making it interpretable, which led us to use techniques like Principal Component Analysis (PCA) and t-distributed stochastic neighbor embedding ( t-SNE). With 1,000,000 rows with 79 features on 39 instruments, visualization will always be a challenge, but these techniques allowed us to map the high-dimensional data into 2D and 3D spaces. PCA specifically helped identify components that captured the majority of variance in the data, making the trends more understandable. t-SNE, on the other hand, preserved the local structure of the data, enabling us to uncover clusters and non-linear relationships that might otherwise remain hidden. These visualizations not only enriched our understanding of the dataset but also provided compelling insights for decision-making.
One of the most intriguing analyses was examining Lagged Correlations, which quantified how the values of one-time series were related to others over time. By calculating correlations at various lags, we identified leading and lagging indicators that could signal future trends. For instance, the relationship between certain features at a lag of 5 or 10 timesteps could inform predictive models about causation or influence. Visualizing these relationships using correlograms provided a roadmap for creating lagged features, enhancing the Transformer model's ability to capture temporal dependencies.
Finally, we ensured the data was ready for modeling by conducting Stationarity Tests using the Augmented Dickey-Fuller (ADF) test. Stationarity, a key requirement for many time series models, ensures that a series has consistent mean and variance over time. Non-stationary series can lead to misleading model outputs, so we applied transformations like differencing and log transformations to stabilize these properties. By addressing stationarity issues, we ensured that the Transformer could effectively process the data and make accurate predictions.
In closing
This project demonstrates how rigorous data analysis, combined with advanced AI techniques, can unlock insights in complex financial datasets. Given the data, we hold the opinion that a Transformer model will provide an effective tool to solve several issues that plague traditional forecasting algorithms. This project demonstrates how rigorous data analysis, combined with advanced AI techniques, can unlock insights in complex financial time-series datasets. Given the data, we hold the opinion that a Transformer model will provide an effective tool to solve several issues that plague traditional forecasting algorithms.
Our hypothesis is that a Large Time Series Model might solve the following issues.
Need for Capturing Long-Range Dependencies: Key for understanding time series with extended temporal patterns.
Scalability: Addressing large datasets and multiple time series simultaneously.
Generality: Providing a foundation model that can be fine-tuned for specific tasks.
However, the sheer data volume of frequently changing data makes developing such models and keeping them up-to-date a challenge.
The sheer data volume of frequently changing data makes developing such models and keeping them up-to-date a challenge. But I suppose it is a fun one.
