
Group Sequence Policy Optimization vs Group Relative Policy Optimization
Two generational advancements in a duel of dynamic decision dynamics

Remember when earlier this year, DeepSeek’s release of DeepSeekMath and Group Relative Policy Optimization (GRPO) made training a state-of-the-art model dramatically cheaper? The follow-up release of DeepSeek-R1 amplified the effect, and the result was a sudden sell-off of AI stocks. Then only a few months later, Alibaba’s Qwen team introduced Group Sequence Policy Optimization (GSPO), the reinforcement learning method behind Qwen3-Instruct, Qwen3-Coder, and Qwen3-Thinking.
Reinforcement learning is emerging as a primary driver for improving language model reasoning capabilities. A fundamental question is whether current reinforcement learning algorithms merely sharpen the base model’s distribution around problems it can already solve.
In this post, I will explain and compare two reinforcement learning algorithms that have recently reached some prominence in the industry:
Group Sequence Policy Optimization (GSPO) and
Group Relative Policy Optimization (GRPO).
GRPO was introduced by DeepSeek through their "DeepSeekMath" paper earlier this year, and it gained widespread attention with the release of DeepSeek-R1. This new method made training a SOTA model significantly cheaper and led to an abrupt sell-off of AI stocks.
GSPO, on the other hand, is the RL algorithm used to train the latest Qwen3 models, including Qwen3-Instruct, Qwen3-Coder, and Qwen3-Thinking. The GSPO paper was published only a few weeks ago, making it one of the newest RL methods in the field.
Both GSPO and GRPO are reinforcement learning algorithms designed to enhance the reasoning capabilities of Large Language Models.
Traditionally, the actor-critic RL algorithm Proximal Policy Optimization (PPO) (Schulman et al., 2017) is used in the RL fine-tuning stage of LLMs. GSPO and GRPO represent departures from traditional token-level optimization methods by focusing on group-based and sequence-level optimization, respectively.
Let me explain.
Group Relative Policy Optimization (GRPO)
GRPO is a reinforcement learning algorithm that emerged as an alternative to traditional methods like Proximal Policy Optimization (PPO) and has gained recognition for its memory efficiency and mathematical reasoning capabilities.
Let’s say we want to predict the next word in this sentence.

In the traditional PPO, the value function is trained alongside the policy model. The value model is used to predict the expected return from each option. Policies (π) are adjusted based on the action the RL algorithm took. The advantage value is derived if the received reward is higher or lower than the expected reward (we received from the value model). If the advantage value is positive, then we can conclude it was a good action, and if it’s negative, it was a bad action. We want to encourage good actions and discourage bad actions and adjust the policy accordingly. To prevent the model from making overly large updates that could cause it to forget what it has already learned, PPO uses an importance ratio. Think of it as a kind of “change limiter” that compares the new strategy to the old one and ensures updates are cautious yet still large enough to drive learning. In the PPO, the importance ratio is calculated at token level.

{kind=link}
GRPO foregoes the value model, instead estimating the baseline directly from group scores. More specifically, for each question q in the training dataset, the GRPO algorithm samples a group of outputs {o1,o2,⋯,oG} from the old policy and then optimizes the policy model expressed as the GRPO objective.
Key Characteristics of GRPO
That GRPO eliminates the need for a separate value function (critic network) is important for efficiency reasons, because the value model is typically another model of comparable size to the policy model. This makes GRPO significantly more memory-efficient than PPO. Instead of using external evaluators to guide learning, it generates multiple responses for each question and uses relative scoring within groups. The GRPO algorithm evaluates groups of responses relative to one another rather than relying on absolute scores from external critics. This approach enables more efficient training by using the average score within a group as a reference point to determine which responses should be reinforced.
In GRPO, the advantage function is approximated as the normalized reward of each response within its group, significantly simplifying the mathematical complexity compared to traditional methods.
In pseudocode, this looks like this:

Here is a sample implementation of how I think the algorithm could be implemented. If you are keen, I can send you the full code.
def train(self,
task_prompts: List[torch.Tensor],
num_iterations: int = 10,
batch_size: int = 8,
num_grpo_iterations: int = 3,
num_outputs_per_query: int = 4,
steps_per_iteration: int = 100):
"""
Main training loop implementing Algorithm 1.
Args:
task_prompts: List of task prompts D
num_iterations: Number of outer iterations I
batch_size: Batch size for sampling
num_grpo_iterations: Number of GRPO iterations μ
num_outputs_per_query: Number of outputs G to sample per query
steps_per_iteration: Number of steps M per iteration
"""
print(f"Starting GRPO training for {num_iterations} iterations...")
for iteration in range(1, num_iterations + 1):
print(f"\n=== Iteration {iteration}/{num_iterations} ===")
# Step 3: Set reference model
reference_model = PolicyModel(self.vocab_size)
reference_model.load_state_dict(self.policy.state_dict())
reference_model.eval()
# Steps 4-9: Training steps
for step in range(1, steps_per_iteration + 1):
if step % 20 == 0:
print(f" Step {step}/{steps_per_iteration}")
# Step 5: Sample batch
batch = self.sample_batch(task_prompts, batch_size)
# Step 6: Update old policy model
old_policy = PolicyModel(self.vocab_size)
old_policy.load_state_dict(self.policy.state_dict())
old_policy.eval()
# Step 7: Sample G outputs for each query
outputs = self.policy.sample_outputs(batch, num_outputs_per_query)
# Step 8: Compute rewards
flattened_outputs = [output for query_outputs in outputs for output in query_outputs]
flat_rewards = self.compute_rewards(flattened_outputs)
# Reshape rewards back to [query][reward_model][output] structure
rewards = []
output_idx = 0
for query_outputs in outputs:
query_rewards = []
for rm_idx in range(len(self.reward_models)):
rm_rewards = []
for _ in query_outputs:
rm_rewards.append(flat_rewards[rm_idx][output_idx])
output_idx += 1 if rm_idx == len(self.reward_models) - 1 else 0
query_rewards.append(rm_rewards)
rewards.append(query_rewards)
if rm_idx == len(self.reward_models) - 1:
output_idx = 0
# Correct reward structure
rewards = []
for query_idx, query_outputs in enumerate(outputs):
query_rewards = []
for rm_idx in range(len(self.reward_models)):
rm_rewards = []
for output_idx in range(len(query_outputs)):
global_idx = sum(len(outputs[i]) for i in range(query_idx)) + output_idx
rm_rewards.append(flat_rewards[rm_idx][global_idx])
query_rewards.append(rm_rewards)
rewards.append(query_rewards)
# Step 9: Compute group relative advantages
advantages = self.compute_group_relative_advantage(outputs, rewards)
# Steps 10-11: GRPO iterations
for grpo_iter in range(num_grpo_iterations):
self.policy_optimizer.zero_grad()
# Compute GRPO objective
loss = self.grpo_objective(old_policy, batch, outputs, advantages)
# Update policy
loss.backward()
torch.nn.utils.clip_grad_norm_(self.policy.parameters(), 1.0)
self.policy_optimizer.step()
# Step 12: Update reward models
self.update_reward_models(outputs, rewards)
print("\n=== Training completed ===")
return self.policy
But probably their GitHub is a better place to start.
One of the problems of GRPO was that it exhibited severe stability issues during training, often resulting in catastrophic and irreversible model collapse. The Qwen team identified that the instability of GRPO stems from the fundamental misapplication and invalidation of importance sampling weights in its algorithmic design.
Group Sequence Policy Optimization (GSPO)
GSPO is the more recent development introduced by Alibaba's Qwen team as an evolution beyond GRPO. Specifically, GSPO is the algorithm supporting reinforcement learning training of the recent batch of Qwen3 models (Instruct, Coder, Thinking). As you know, I have been a big fan of the Qwen team since my work on Game Theory and Agent Reasoning.
What makes GSPO different is that it represents a sequence-focused approach to policy optimization compared to the group averages of GRPO.
Key Characteristics of GSPO
Unlike previous algorithms that use token-level importance ratios, GSPO defines importance ratios based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. I.e., GSPO calculates one importance ratio for the entire sequence using the probability of the whole response.
In reinforcement learning, the importance ratio (also called importance weight or likelihood ratio) is used for off-policy learning and importance sampling and serves to correct for distributional mismatch when data was collected under the old policy, but we want to optimize the new policy. Or, in other words, it measures how much the entire response's probability has changed between the old and new model
In addition, in GRPO, when generating language, the Qwen team observed that sequence-level importance weight has a clear theoretical meaning: it reflects how far the response sampled from the old model deviates from the new model, which naturally aligns with the sequence-level reward and can also serve as a meaningful indicator of the clipping mechanism.
I specifically loved this quote from the paper (emphasis mine)
The failure of the token-level importance weight points to a core principle: the unit of optimization objective should match the unit of reward. Since the reward is granted to the entire sequence, applying off-policy correction at the token level appears problematic. This motivates us to forego the token-level objective and explore utilizing importance weights and performing optimization directly at the sequence level.
One of GSPO's most significant advantages is its ability to stabilize Mixture-of-Experts (MoE) reinforcement learning training, which has traditionally been challenging due to the complexity of routing mechanisms in MoE architectures. Also, as Qwen has impressively shown, empirical results demonstrate that GSPO not only matches but exceeds GRPO's performance across various metrics while providing greater stability and training efficiency.
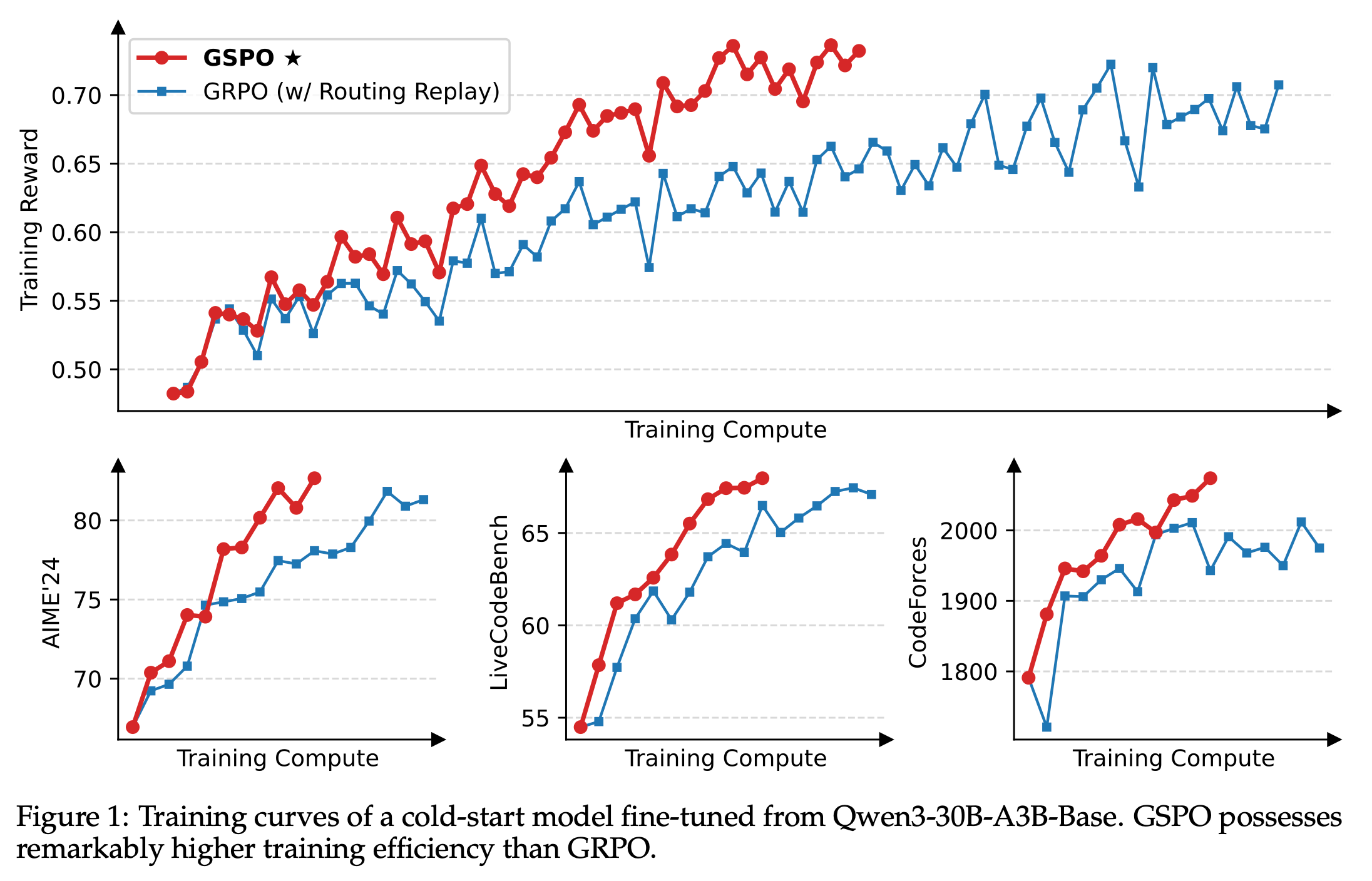
source - figure 1
Comparative Analysis
I think we can understand that GSPO demonstrates a superior training efficiency when compared to GRPO through its sequence-level optimization approach. While GRPO focuses on group-relative comparisons, GSPO's sequence-based importance ratios provide more direct optimization paths. GSPO shows significant advantages in training stability, particularly evident in its ability to handle complex architectures like Mixture-of-Experts models. GRPO, while stable for standard architectures, lacks the specific optimizations needed for MoE training. Both algorithms offer memory efficiency improvements over traditional methods like PPO, but they achieve this through different mechanisms. GRPO eliminates the critic network entirely, while GSPO optimizes memory usage on top of this through sequence-level processing. Current research suggests that the sequence-level approach provides meaningful improvements over group-relative optimization. And finally, GRPO offers mathematical simplicity and elegance through its normalized reward approach within groups. GSPO, while more complex in its sequence-level calculations, provides infrastructure simplification benefits that may offset implementation complexity.
Limitations and Considerations
GRPO faces several significant limitations when applied to large-scale language model training. The algorithm demonstrates reduced effectiveness as training scales increase, struggling to maintain stability and performance with very large models and datasets. Additionally, GRPO shows particular weaknesses when working with complex architectures like Mixture-of-Experts (MoE) models, where the sparse activation patterns create additional instability challenges that require workarounds like Routing Replay strategies. These architectural limitations, combined with generally lower training efficiency compared to newer methods, make GRPO less suitable for cutting-edge large language model development.
In contrast, GSPO's primary limitations stem from its relative novelty rather than fundamental algorithmic weaknesses. As a recently developed algorithm, GSPO has undergone less extensive real-world testing across diverse scenarios and use cases, creating some uncertainty about its performance in edge cases or unexpected conditions. The implementation of GSPO may initially require more sophisticated engineering compared to established methods, potentially creating barriers for teams without advanced RL infrastructure expertise. Furthermore, the limited availability of comprehensive comparative studies means that practitioners have fewer benchmarks and best practices to guide their implementation decisions, though early results suggest these limitations are temporary rather than inherent to the algorithm's design.
Conclusion
GSPO addresses one of GRPO’s main weaknesses: its instability in large-scale and Mixture-of-Experts (MoE) training. The sequence-level approach taken in GSPO offers a path to more stable and efficient optimization without losing the efficiency gains that made GRPO so appealing. While GRPO shocked the world earlier this year by making model training substantially cheaper, it also established important foundations for group-based policy optimization in language model training. GSPO then represents a significant advancement, addressing key limitations in training efficiency and especially stability. For new implementations, particularly those involving large-scale models or complex architectures, GSPO appears to offer superior capabilities. However, GRPO remains valuable for scenarios prioritizing simplicity and interpretability, especially in mathematical reasoning applications.
The choice between GSPO and GRPO should be based on specific requirements, including model scale, architecture complexity, infrastructure constraints, and performance objectives. You should probably consider GSPO because of GRPO’s stability issues. Unless, of course, there is something else coming up.
What I liked about the GSPO approach specifically is how many deep but extremely simple insights are in the paper.
Key Research Papers
GRPO
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models - ArXiv:2402.03300
What is the Alignment Objective of GRPO? - ArXiv:2502.18548
Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening - ArXiv:2506.02355
Reinforcement Learning with Verifiable Rewards: GRPO's Effective Loss, Dynamics, and Success Amplification - ArXiv:2503.06639
GRPO-LEAD: A Difficulty-Aware Reinforcement Learning Approach - ArXiv:2504.09696
GSPO
Group Sequence Policy Optimization - ArXiv:2507.18071 (Primary paper introducing GSPO)
Hybrid Group Relative Policy Optimization: A Multi-Sample Approach - ArXiv:2502.01652 (Extensions and applications)
