


OpenAI Agents SDK: Power, Potential, and Pitfalls
When the Framework Works but the Agent Doesn't: OpenAI's Financial Research Struggles

Earlier this month, OpenAI launched a new SDK for building agents. This follows my assumption that all large model providers will also offer efficient and embedded agent frameworks.
The initial verdict— as one would expect. It’s nice. OpenAI’s framework is a solid piece of engineering. Which leads me to thinking, why would I use Langchain/graph, LlamaIndex, or CrewAI when I can just use this?
And it works out of the box? Probably my main concern would be vendor lock-in. But besides that, if I could replace the AI with a generic call to another LLM, it would be pretty much perfect. But I digress.
Let’s focus first on what makes this framework so good.
OpenAI defines agents as system that works independently to perform tasks (to act) on the user’s behalf.
Agents SDK is the next product iteration of the Swarm research project, slowly pushing agent tech to a production-ready technology readiness level.
What makes the SDK better than swarms is that the agents can now be orchestrated through handoffs, i.e., tools for transferring control between agents. And, now agent workflows also support tracing, allowing you to view, debug, and optimize your agent ops.
But how does it work in detail? And more importantly.
Is it reliable?
Let’s dive right in.
Setup
I suppose if you already have it installed, you can skip this step, but we never know.
So here you go.
You need to clone the GitHub repo, then you go into the folder and create a virtual environment.
git clone https://github.com/openai/openai-agents-python.git
cd openai-agents-python/
python3.11 -m venv venv
source venv/bin/activateOpenAI uses venv. It’s a package manager that I also use and like. I used Python 3.11. Then you activate the virtual Python environment with the “source” statement.
pip install open-ai-agentsThen OpenAI recommends installing the agents package as shown above. Since I want to use a pre-built example for this exercise, it makes sense to have the code available. There is a reason. Before we can run the example, we need to adjust a script called “financial_research_agent.py” that you can find in the subfolder “examples”. Here we need to hand over your OpenAI API key.
import os
os.environ["OPENAI_API_KEY"] = "<YOUR KEY>"Once this is done, you could theoretically run it with this statement.
python3.11 -m ./examples/financial_research_agent.mainBut why would you do it? You don’t know what the agent does yet!
Financial Research Agent (FRA)
In a nutshell, the FRA orchestrates a light process for financial research. From planning searches to generating and verifying a final financial report, the agent utilizes a series of AI agents specialized in different tasks, such as financial analysis, risk assessment, web searching, and report writing.
DeepSearch has become increasingly popular recently, and my own older work on the topic still works. So we need to understand what this agent, or better this multi-agent, does as it creates a research analysis for a given query.

As you can see, the overall architecture of the agent is quite basic.
The user provides a search query to the agent, and then the Planner Agent creates a structured search plan that can help find a solution for it. The Search Agent then executes the Search and hands over the result to a group of specialized sub-agents. Then we have a verification judge at the end to check if the provided report is good or not.
For all of the agents, system prompts are extremely simple.
Here is an example for the planner agent:
Which doesn’t mean it has to be ineffective. I doubt, however, that the partial prompt “headlines, earnings calls, or 10-K snippets[…]” will be impactful down the line. And this opinion was formed on several years of actual agent ops work experience building such systems in production.
The agent is not only the prompt; it needs to be instantiated.
This is done like this:
planner_agent = Agent(
name="FinancialPlannerAgent",
instructions=PROMPT,
model="o3-mini",
output_type=FinancialSearchPlan,
)Here, the name is provided for tracing and orchestration. A system prompt is handed over to define the role and personality the agent should have.
And “FinancialSearchPlan” is a simple Pydantic BaseModel that helps with response reliability control. Once the search plan is written, the Search Agent then begins to crawl by executing the searches in sequential order and gathering information. Important to note is that this agent uses the recently launched Websearch Tool and not Tavily, DDG, or Serpapi.
Then the raw search results are handed over to the Writer Agent. I suppose that OpenAI’s web search tool already has a predefined format to return the search results that make it easy for the writer agent to compose the report.
The workflow orchestration is really interesting here, though.
Both the risk agent and the financial agents are instantiated as tools.
Instantiating agents as tools is different from handoffs in two ways:
In handoffs, the new agent receives the conversation history. As a tool, the new agent receives generated input.
In handoffs, the new agent takes over the conversation. As a tool, the conversation is continued by the original agent.
In code that looks like this:
from .agents.risk_agent import risk_agent
risk_tool = risk_agent.as_tool(
tool_name="risk_analysis",
tool_description="Use to get a short write‑up of potential red flags",
custom_output_extractor=_summary_extractor,
)The function “clone” is defined here and simply makes a copy of the generic agent class, yet with the given arguments changed.
writer_with_tools = writer_agent.clone(tools=[fundamentals_tool, risk_tool])
input_data = f"Original query: {query}\nSummarized search results: {search_results}"
result = Runner.run_streamed(writer_with_tools, input_data)Here we can observe how the agent then runs its agentic pattern through an instance of the “Runner” object by being provided with the original query and the result of the plan and search operations.
Once this is complete, the Verifier Agent receives the query and the final report and performs a final review of the final report for accuracy. The prompt and function definition for that task are quite basic and such omitted here.
Flow
We have seen that the agentic process follows a sequential flow: planning searches → performing searches → writing report → verifying report → outputting the final result.
When considering the data flow, we will notice that each agent produces specific outputs that feed into the next stage. The writer agent can dynamically invoke the analysis tools when needed, and the final verified report is presented to the user
At its core, this flow follows an asynchronous workflow, meaning that multiple tasks, such as web searches, can run in parallel, making the process more time-efficient. The manager interacts with several sub-agents to gather information, analyze financial data, and generate a structured report.
How It Works in Practice
Curious about what this framework can do, I asked it to analyze Ubisoft. A company that has lost about 73% of its market cap over the last 5 years and has been in the news for a lot of wrong reasons recently.
And thus, it might be a great candidate for a turnaround story.

Q: “Write a report about Ubisofts recent quarter”
Good news first, the script worked well out-of-the-box and provided a quite nice report. *Looking over angrily at LangGraph/Chain”.
Even though there is no way for me to validate easily if the generated report is accurate.
The agent performed all these steps correctly:
Generate a search plan to identify the most relevant financial data sources.
Perform web searches asynchronously, retrieving information efficiently.
Analyze key financial metrics using specialized sub-agents.
Compile a financial report, incorporating insights from different agents.
Verify the report's accuracy, ensuring the final output is trustworthy.
Display the final report along with any potential follow-up questions.
Here is a screenshot snippet of the report that the agent had produced.

Yes, it’s a text.
But it will take time to validate if the output of the agent makes sense or not. And this is important for all forms of agentic workflows. Not only for financial analysis. But we already know that LLMs usually perform poorly with quantitative elements.
I suppose it was a fun read that cost me USD 1.72.
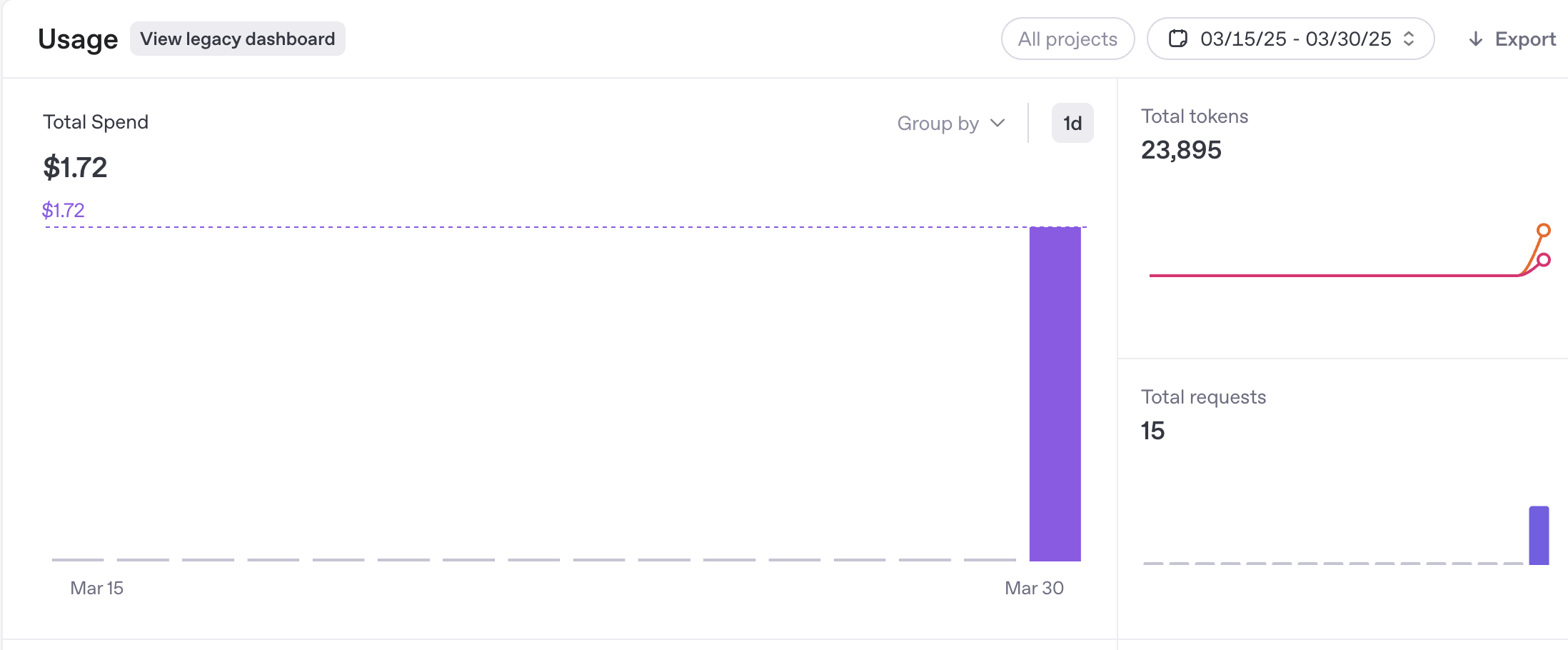
As I had mentioned above, I wish there were an easy way to integrate local or HF-hosted free models with the agent. Since it is important to understand how much cost was incurred by running this agent. I created, as usual, a new API key and let the agent do its job. It spent USD 1.72 on preparing the research report. Not only from an RoI perspective, but also from a business model perspective, this is interesting. If you run a report like this daily for a portfolio+watchlist of about 100 stocks, and USD 1,72 is a nominal price, then you would likely incur (100*1.72*20) == USD 3,440 cost per month.
For most retail investors, this is not possible.
Overall, however, I think there is something there.
The agent is powerful but needs a lot more work in context & prompt management. But, orchestration might actually work exactly in this way. Sources would be great, though. But let’s build on that.
Please subscribe or recommend. It would help me a lot to grow this channel.
Thank you!
How did you like this post?
