
How should Agentic User Experience Work?
Future of Work with OpenAI Atlas, Perplexity Alpha, Claude Skills, and News Explainer

It always fascinated me how LaForge in Star Trek: TNG could easily recalibrate the Warp Drive using only a selection of standard interfaces, a highly efficient “computer’, and a small selection of hand tools. Considering where we are in our current timeline, what if he worked with hyper-efficient AI agents (nanites 3.0) to support him in his work?
When I think of agents, I think about them like a co-worker who has recently joined the company and doesn’t have much knowledge of the existing intrinsic corporate knowledge. When we engage with our human counterparts, we (well, I usually), set up a meeting or write a detailed email explaining the tasks and identifying open questions to clarify exactly what the output should be (interaction 1). Then asynchronously, the colleague starts working on the tasks and a finite time later returns with some result (interaction 2). If the result hits the expected output, the task is completed; if there are refinements needed, then the work relationship continues. Between interaction 1 and interaction 2, a lot of things might change. My expectation of the expected outcome might change as I also learned more through the follow-up to interaction 1, or there are external factors that might influence the expected outcome.
Recently, OpenAI has launched with Atlas, a Google Chrome competitor that aims to enhance your browsing experience and become your window to the Internet. I.e., when you are researching a topic, you get an answer machine in the form of ChatGPT bolted on the browsing experience.
Perplexity had already launched a browser a while ago called Comet, which is also based on Chromium and obviously was launched to solve a very similar goal.
To be the primary gateway for users to access the Internet.
The fact alone that all of these leading AI companies decided to build on top of an existing open-source project and not use their own code tools to build something entirely new, built for the purpose of i, is crazy for me.
Well, I suppose that since both have a similar UI to Google Chrome, most people won’t have a problem switching. This is an important point since you don’t need to retrain users on a new interface.
And then there is Claude Skills. A recent addition to the Claude capability family that aims to improve procedural task following within the Claude ecosystem.
"Skills are folders that include instructions, scripts, and resources that Claude can load when needed.”
What all of these have in common is that they aim to improve the capabilities of their agent while working off a standard user interface.
In this post, I will be exploring
A Special Purpose News Explainer App,
ChatGPT Atlas,
Perplexity Comet, and
Claude Skills
Over the last weeks, I have been pondering this question:
How does the perfect user experience for AI Agents look like?
So I started to explore this question through a Claude vibe-coded Smolagents-based NewsParser, and now I am ready to share some initial findings about it.
So what am I trying to understand here?
Hypothesis 1: Agentic Code is the future of No-Code.
Hypothesis 2: Agentic execution is asynchronous, not chat-based.
Hypothesis 3: Agentic Coding can iterate quickly over product variations.
Hypothesis 4: Special-purpose interface patterns beat general-purpose ones.
Hypothesis 5: A robust way to provide Standard Operating Procedures to agents is through markdown files.
There are many ways to structure a useful user experience. And with Apple’s spatial computing, we have seen groundbreakingly different ones. However, to everyone who has ever worked in an office, mouse and keyboard beat touchscreens and voice interfaces many times over. Now that agents are joining the workforce, though, workflows will be reorganized again, embedding a cognitive fabric deep into the organizations. The implications are obvious when considering operational resilience and productivity trade-offs.
The News Explainer
In my job, I have to read a lot. Staying up to date with recent trends helps me provide a better service to my clients, so obviously, I scratched my own itch and created a news tool.
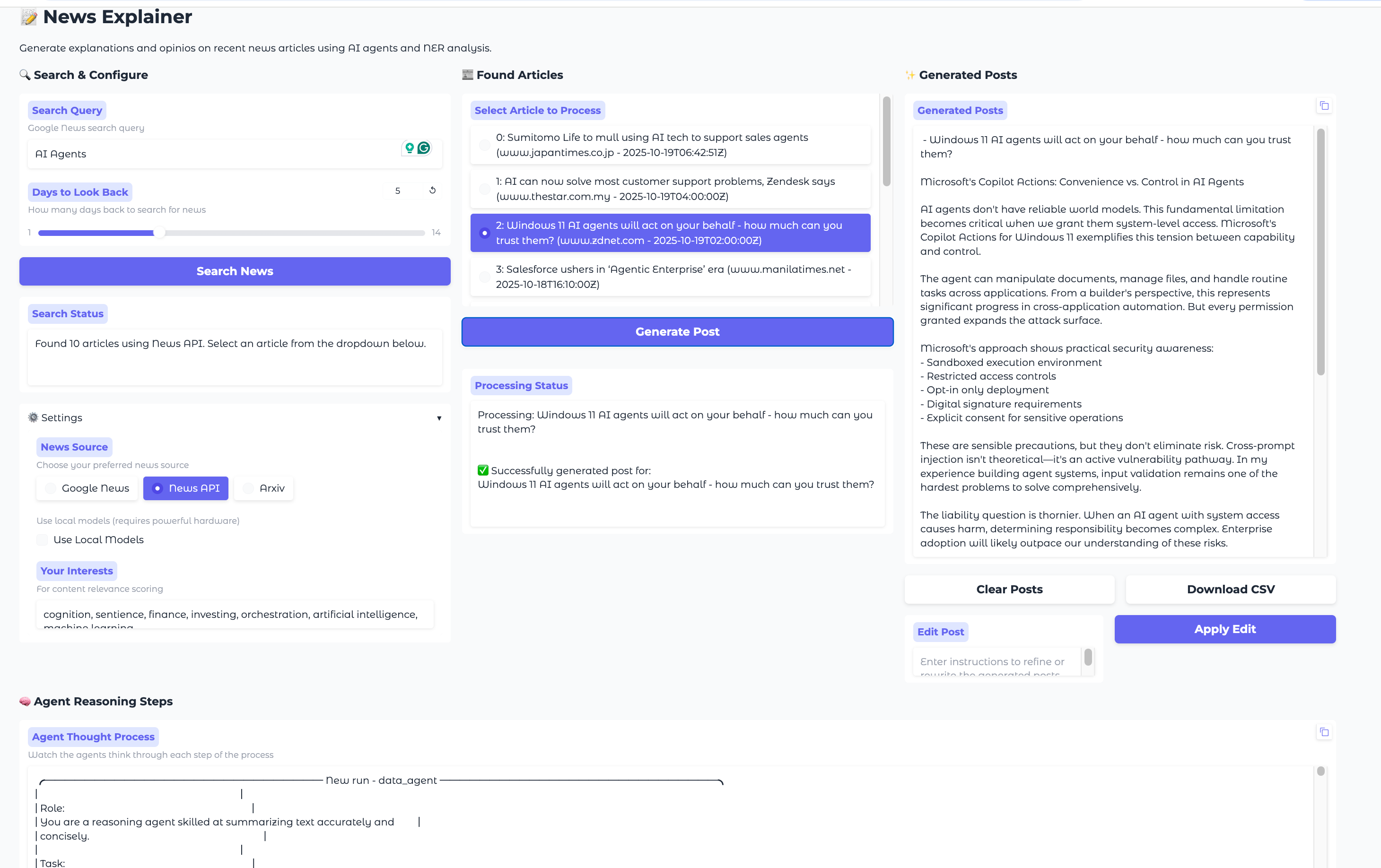
For you, it might be a monstrosity of UX mistakes, but for me, it represents a workflow for a specific problem. And in that, it is not a general-purpose interface. And in that it’s fine. Claude and I have been iterating on it for the last weeks now. And that process was remarkably efficient.
One of the immediate insights here is that I could iterate quickly over new interface ideas with the code being implemented and tested every time anew automatically.
If you are a paying member, I can send you the code. Just reach out via chat.
GUI for One
After doing this, I ended up with just the right solution for myself. Obviously, there is no expectation to make this a product or roll this out to the larger team. For me, personally, it is an effective way to communicate with the underlying agents. When I think about agents, I think about them like a colleague, maybe a fresh intern, who I can give a task to that needs solving.
So how does it work?
The full agentic reasoning pipeline consists of 4 sections.
Data Retrieval → API calls that gather news articles via API.
Selection & Processing → Provide a quick way to screen and rank by relevance.
Reasoning & Generation → Produce entity-based and symbolic reasoning summaries.
Transparency & Validation → Review logic and create an article about it.
By that, I think my UI embodies practices that allow me to engage my AI agents for journalistic or analytical contexts by combining automation with explainability, user oversight, and clear data provenance.
Search & Ingestion
My interface should quickly configure how my AI agents and I retrieve information from external sources and under what conditions. This includes mapping of external data into a standard format. It is also tasked with translating user intent (what to search, where to look, and how to process results) into structured retrieval parameters.
But this post is not about data processing.
These are the UI Components I implemented:
Search Query box: Lets the user define the topic or keyword (e.g., “AI Agents”). There is a blacklist of sources I purposefully exclude if supported by the data source.
Days to Look Back slider: Determines how far into the past the agent should search for news. I mostly only look at today's news since I work with it daily, but I noticed that sometimes I want to see how different data sources have covered a specific event, it makes sense to look deeper into the past. Everything older than 14 days is already too old for what I am trying to solve for.
Search News button: Initiates an API call (to NewsAPI, Google News, or arXiv) to fetch relevant articles. Currently, I track these three data sources. API calls are incredibly straightforward.
Search Status box: Displays how many articles were found, confirming successful data acquisition.
Settings dropdowns: Allow source selection (Google News, News API, arXiv) and interest weighting (topics like “cognition,” “AI,” “orchestration”). Note: the Google News Python package suffers from frequent rate limits. Terrible for testing, but for a daily glance, it’s good enough.
Use Local Models toggle: Suggests the ability to run agent models locally for privacy or performance. None of the tasks given to the agents is necessarily hard. And especially the NER ModernBert model can run locally for free on 4-year-old consumer hardware.
Articles Selection
The middle section of my user interface. Here, I want to be able to quickly parse what happened for the keywords I was looking for.
UI Components:
List of articles: Titles and URLs of the news pieces fetched. If I find the title interesting, I click the link and review the source.
Select Article to Process dropdown: A simple radio button to press for which article the agents should review. My next change here will be to use more than one datasource to hand over to the agent.
Generate Post button: Triggers the reasoning and content generation process. Once I click this button, the post-analysis workflow begins. I currently run about 6 agents here, which reason over the identified named entities, summarize the article, and symbolic reasoning instructions following the sense→ symbolize → reason → act pattern.
Processing Status box: Since this whole process can take some time, I think it’s important to provide streaming feedback (“Processing...”, “Successfully generated post...”) so I know what the agents are working on and what kind of problems.
Overall, this step activates the agent’s reasoning loop, operating off the selected data source, prompting the agent to summarize, interpret, or form opinions about it. The explicit “Generate Post” button provides human control and transparency over when the AI starts reasoning. When I first built the agent, it generated summaries for all news articles and created a “newspaper” PDF.
However, the costs to run it were measurable, and why build something that costs money but adds no value?
Generated Posts
The third column of my UI is for showing the generated artifact and providing the ability to work on the post.
Generated Posts feed: Here, the app displays the generated output. Initially, I had a scrollable array of posts here, but I realized that this doesn’t really help if I want to not only generate a post but also edit it.
Text area for editing: The realization of working with the generated artifact was that sometimes I want to change little things here and there. The tone wasn’t right, or it shows a typical genAI pattern “It’s not just….” despite being explicitly instructed otherwise. The selection here works on sentence level. I.e., I can prompt to replace “this sentence” with “that sentence” But I can also ask to add or remove paragraphs, explain parts, and/or change tones.
Clear Posts button: Resets the workspace for a new run. When I want to work on more than one post.
The third pillar brings the human back in the loop to evaluate the generated information. I think this capability is essential for establishing trust, accountability, and maintaining editorial control over AI-generated insights.
We should never live in a place where we can’t control the AI anymore. Since I do come from a compliance background, being able to understand the activities of the agents is a core quality driver.
Agent Reasoning Steps
I output the chain-of-thought and procedural reasoning behind each step of the content generation process here.
There are two main UI Components:
Structured reasoning trace: Shows the agent’s task breakdown (e.g., “Role: You are a reasoning agent…”, “Task: Summarize text accurately and concisely”).
Indented logical flow: Represents sequential steps the AI takes from input parsing → task definition → reasoning → synthesis.
This section is crucial for AI transparency and debugging. It shows how the AI arrived at its conclusions, improving interpretability, identifying bias, and validating reasoning consistency. The working memory for each agent is managed through a Python dict where each data point, together with the prompt’s output, is maintained and, at process conclusion, stored as a flat file. I was often thinking of integrating the data into a database.
Would be cleaner, probably. But not really something urgent right now.
The benefit of building your own solution is that you have the freedom to do whatever you want with it. And since we are not in a no-code / low-code world. The next steps are only limited by your imagination and your Claude/ChatGPT credits.
What are the established players doing?
Of course, it makes sense to also look at it from the vantage point of UX patterns
ChatGPT Atlas
OpenAI launched ChatGPT Atlas on October 21, 2025, a web browser that mimics Chrome (built on the Chromium Engine). Atlas integrates the assistant directly into the browsing experience, not as an extension, but as the interface itself. It’s currently available globally on macOS, and I’d expect versions for Windows, iOS, and Android to be on the way.
Of course, I had to download it immediately. Maybe one word of caution. Maybe I didn’t read the dialogues properly, but Atlas made itself immediately default browser, breaking authentication flows of other apps like Claude and hijacking Spotlight.
How does Search work?
For me, this is what a new tab looks like. Naturally, I’d expect that the prompt text box in the middle can be used for Search.
So I started with some recent news about a UFC 321 fight I was watching. I suppose the search was quickly executed and provided some information about what went down.
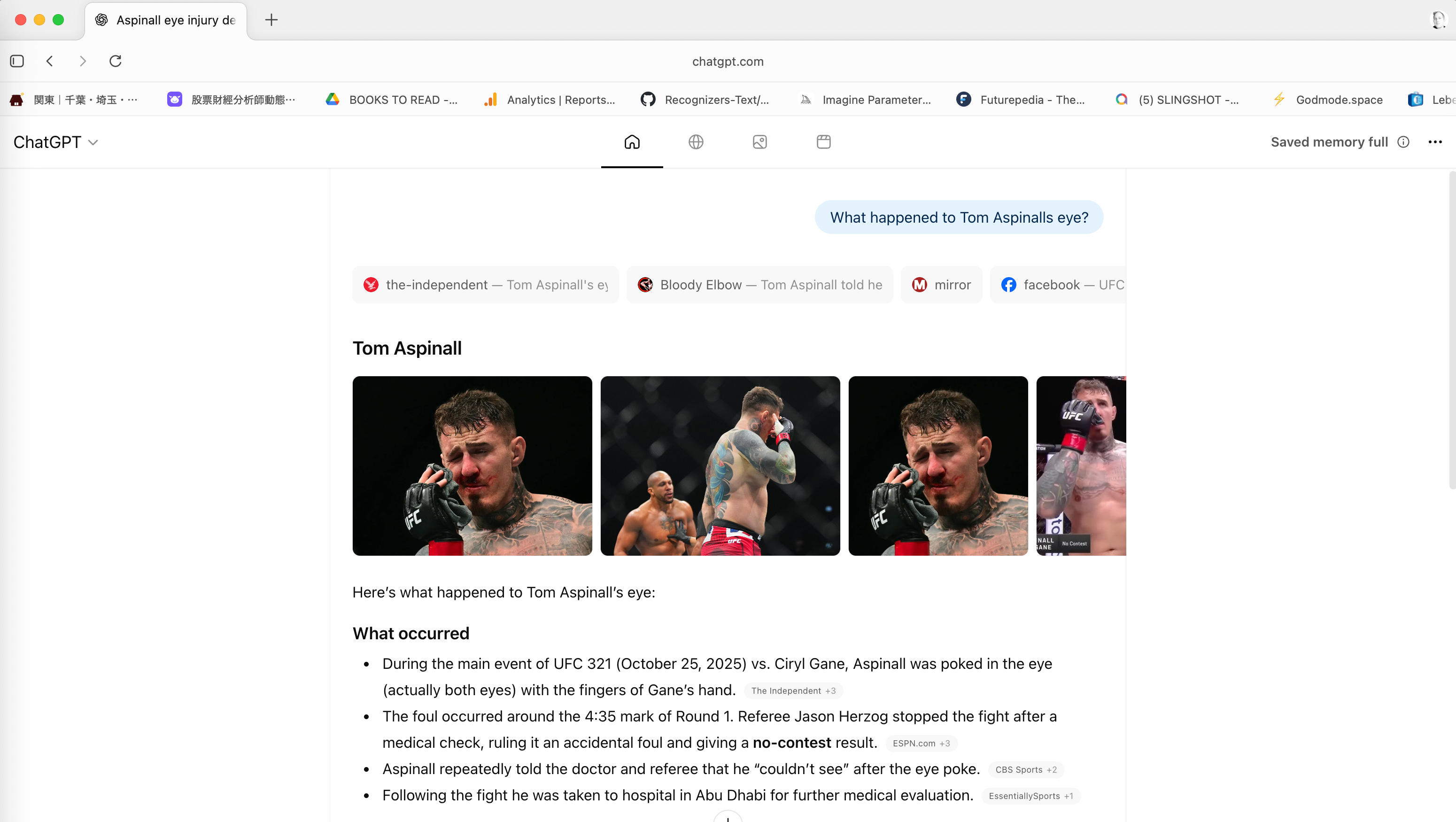
There are 4 icons at the top (Home, Search, Images, and Video). While “Home” is the answer machine, “Search” is indeed providing Search results.
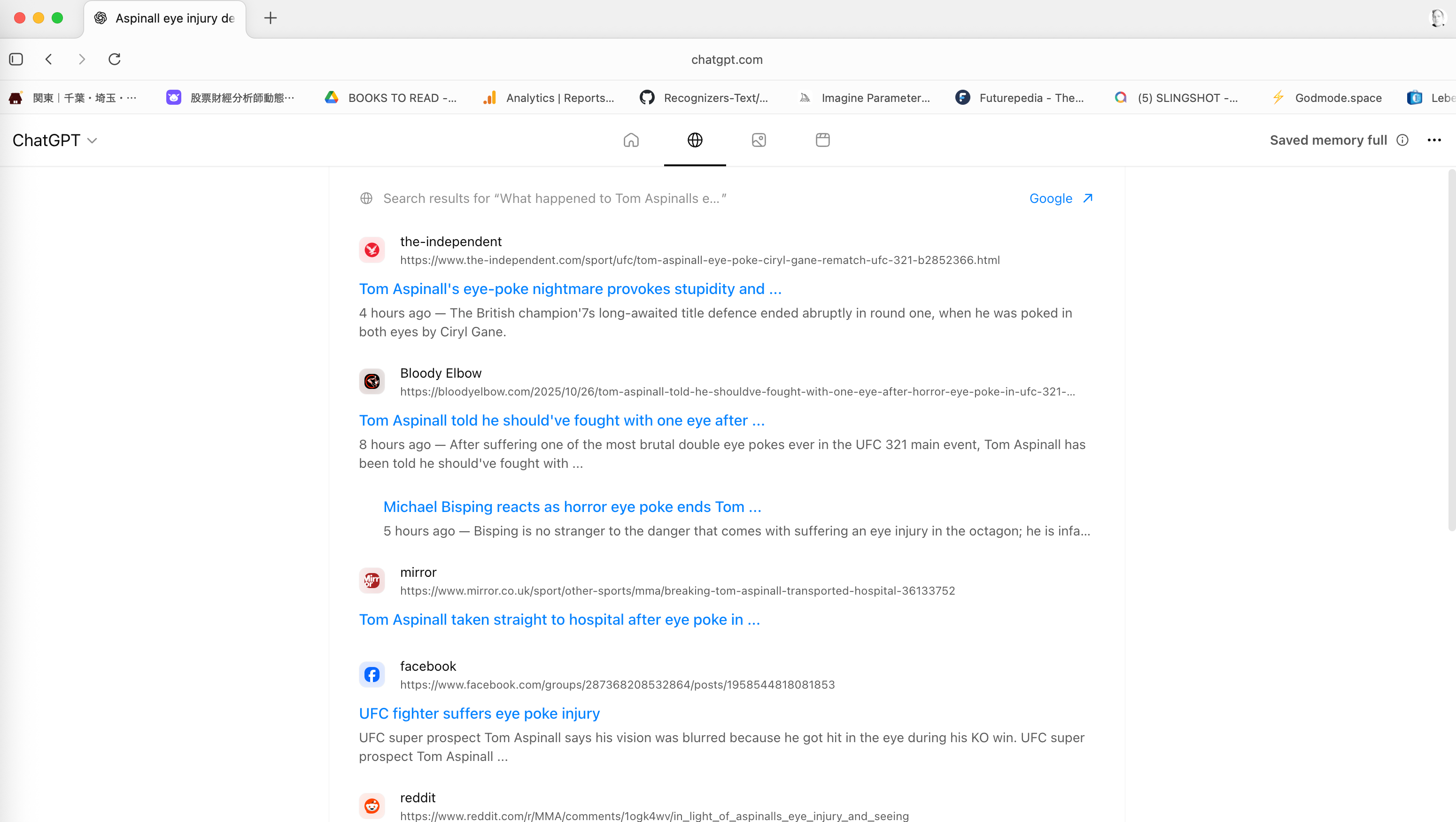
And as you can see through the “Google” link, I’d assume that the search results are coming through Google. So, for all of us who thought that this would be an attack on Google's Search monopoly. Think again.
Besides ChatGPT pestering me to upgrade constantly, nothing special here.
So what does ChatGPT think Atlas’ core features are?
Chat-integrated sidebar for every page: A persistent ChatGPT sidebar next to whatever webpage you’re on, enabling you to ask about or act on the content without switching tabs.
Context-aware assistant: Rather than being entirely detached from the web content, Atlas understands your current tab/page and uses that to provide more relevant responses. And that’s really dumb in a way.
Inline writing-help and editing: In the feature spec, I remember reading that you can highlight text on a webpage and ask the assistant to rewrite, refine, or improve it, directly in-line, but I haven’t seen that feature work.
Built-in memory (“browser memories”): The browser remembers your visited pages, tasks, and workflows so that ChatGPT can bring that context back when needed. Users retain control to view/edit/delete those memories. And that is a privacy nightmare.
Privacy and user-control: While the browser introduces more automation and context tracking, OpenAI highlights that users can manage what is remembered, delete histories, and control the memory features.
Agent mode (preview): For Plus/Pro/Business users (at least initially), the browser offers an “Agent” that can perform multi-step tasks for you, such as research, comparing items, and automating parts of a workflow across tabs.
Noted. Now I want to see how the inline writing-help and context-aware assistant might work.
Let’s assume I have this article I wanted to read.
The first observation is that ad-blockers don’t work, making it hard on Forbes’ site to distinguish content from advertising. Obviously, my motivation to read through this is pretty much zero. Damn, these pages are ugly without ad-block.
So I asked Atlas to “Summarize this article and highlight the top 5 key arguments.”
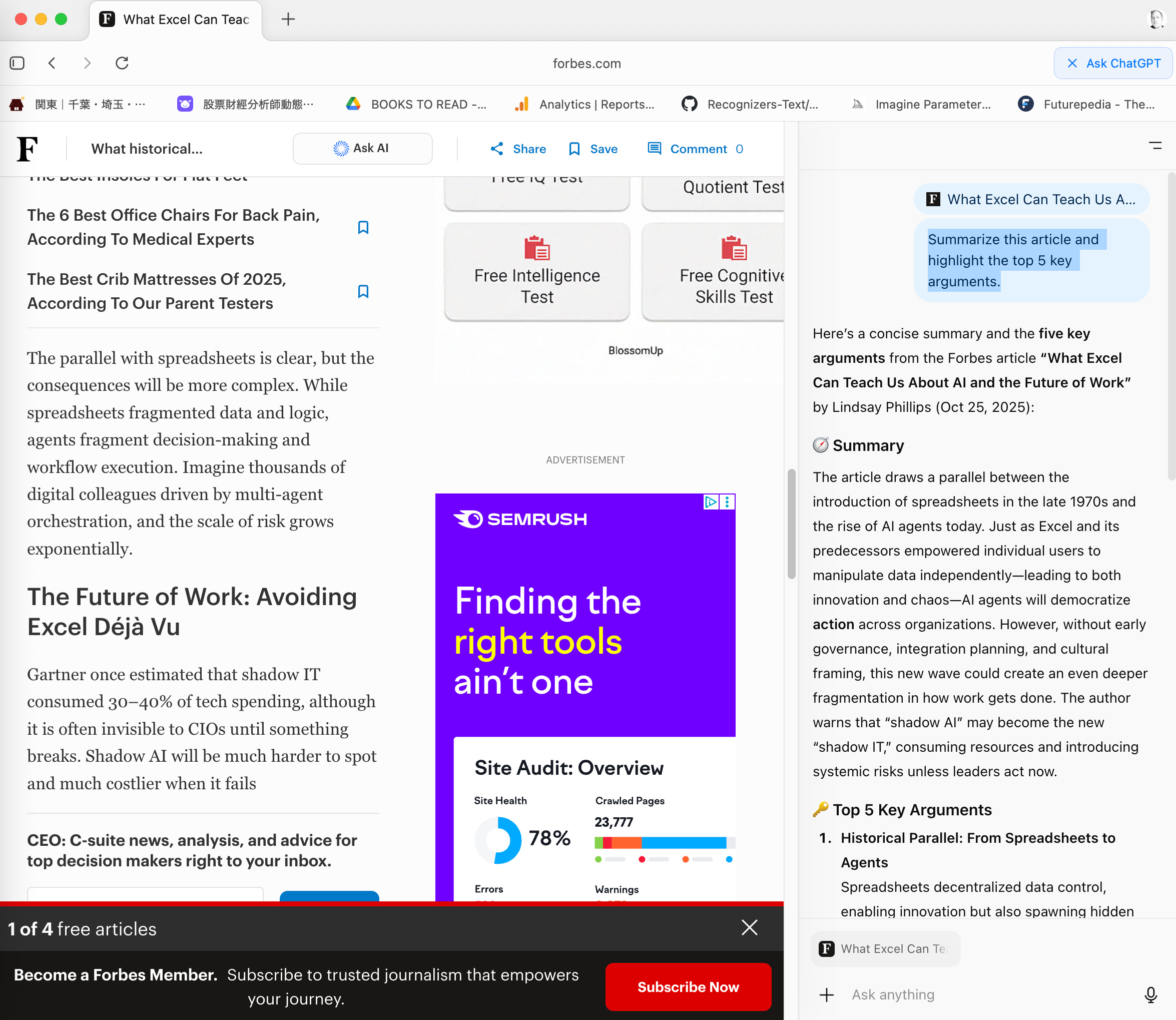
Well, it’s a browser with ChatGPT on the side. Doesn’t blow me away just yet.
Interesting to note was that when I asked Atlas to contact the author, it provided me, besides the Forbes contributor page, also with a LinkedIn page. When I clicked the link, Atlas automatically signed me in since I am also already authenticated on Chrome. Make with that information what you want.
When I then asked Atlas to write an introductory message, it complied with
“Hi Lindsay,
I recently read your Forbes piece “What Excel Can Teach Us About AI and the Future of Work”, an insightful comparison that captures both the empowerment and risk in democratizing AI tools. I’d love to connect and exchange perspectives on how organizations can balance agent autonomy with governance and adoption strategy.Warm regards,
Jan
You can see it was written by ChatGPT. Still impressive that Atlas relied on memory to trace my path to the profile from the conversation memory. That means I gave OpenAI the implicit permission to observe every step I take on the Internet.
That doesn’t really make me feel very comfortable. Of course, you can argue that Google and 300 other tracking companies do the same. Still, it’s a concern.
I hate browsing social media websites because doom scrolling is inefficient and only adds to cognitive load. So I asked Atlas, “Find a post in my LinkedIn feed that I must respond to.”. Not totally unexpected, it only explained responses for the two posts that were on the screen at the time and didn’t go further into the timeline. I also asked Atlas to recommend people I haven’t connected with but need to, and it also failed that task. Atlas also failed to find and book me a flight to Tokyo next weekend.
If Sam Altman thinks that 5% is good enough to protect Atlas users from prompt injection attacks, he is mistaken.
Probably what surprised me the most is that Atlas showed me that I have been using ChatGPT for 1410 days (16 December 2021).
Time flies.
Comet
Comet is a browser developed by Perplexity AI. Officially launched on July 9, 2025. Currently, it’s largely free for all users. Built also on the open-source Chromium engine, Comet integrates Perplexity’s AI assistant directly into the browsing experience.
This is how the default page looks:
I suppose everybody starts with the Google UI of 2003. Comet provides the well-established, high-quality results that Perplexity is well known for. From a user experience, though, Comet is unsurprisingly already a couple of steps ahead.
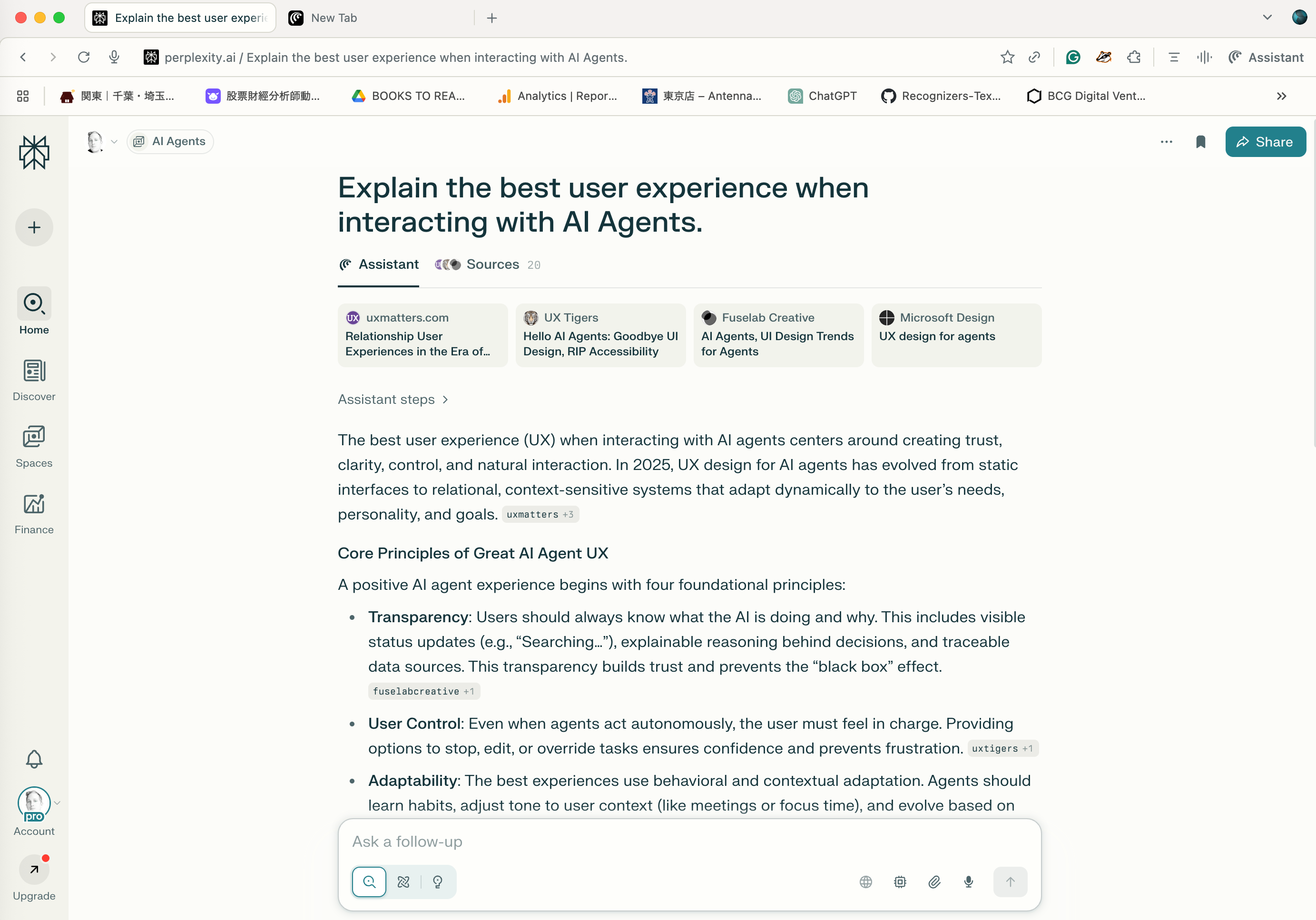
The Discover feature in Comet acts as an intelligent assistant, allowing users to ask questions and explore information without leaving their current browsing context.
Finance is something I covered already, “The Ultimate Guide: Perplexity For Finance”.
Spaces allow users to create dedicated environments within the browser for specific tasks or projects.
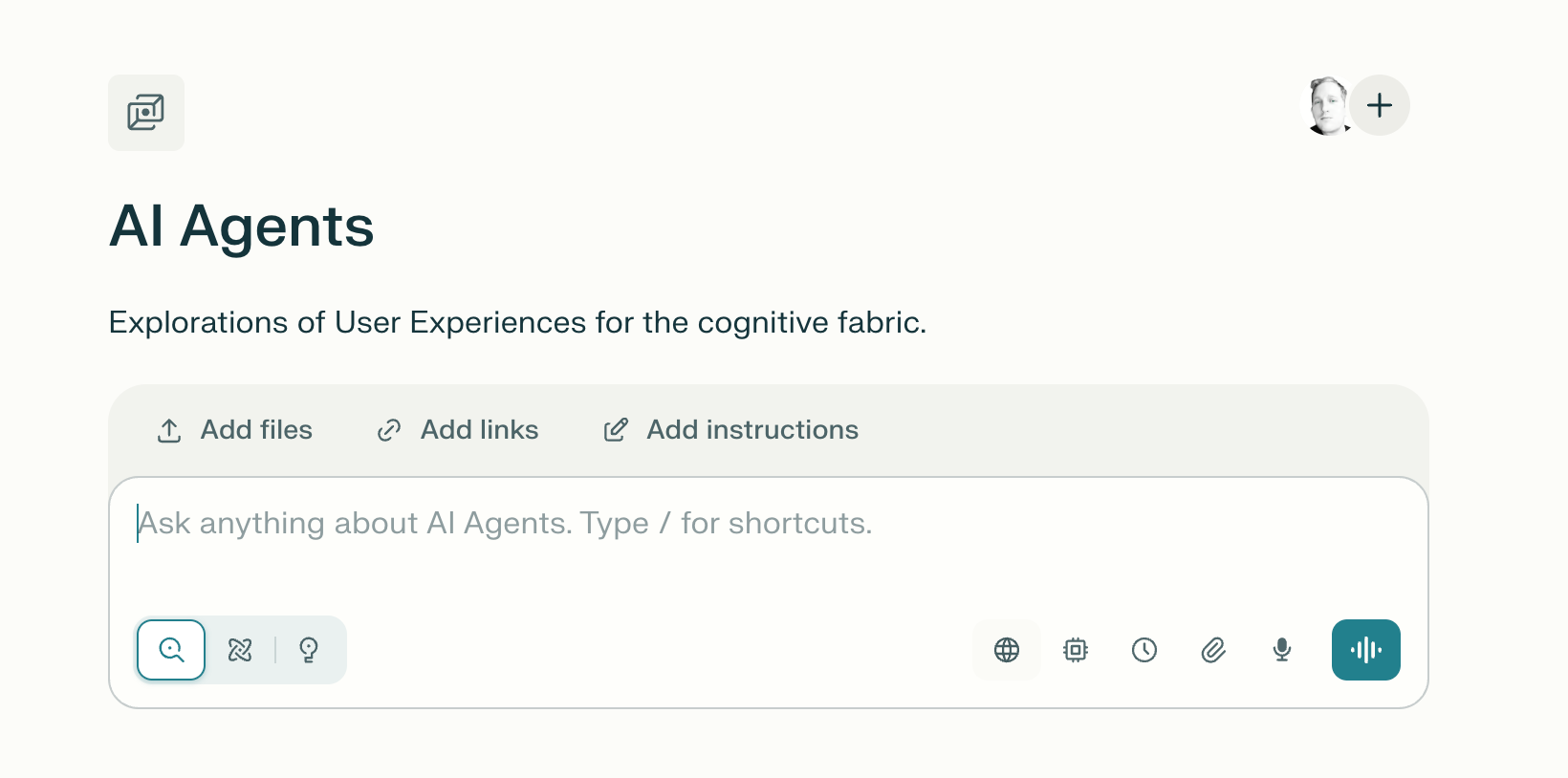
Each space can house its own set of instructions, knowledge, and custom assistants, tailored to particular needs like coding, research, or content creation. By typing “@” followed by the space’s name, it should be possible to activate and interact with these specialized assistants directly within their workflow. It is also possible to add specific knowledge in the form of files, links, or dedicated instructions.
In that sense, it feels very similar to GPTs or Claude Skills.
Claude Skills
Claude Skills were officially introduced by Anthropic on October 16, 2025, as modular extensions built to expand Claude’s reasoning and functional capabilities. And by Claude, I mean the Desktop app. Claude Skills allow agents in Claude to flexibly access domain-specific expertise as needed.
At its core, Skills work off a flat file.

How Skills work
From a structural standpoint, each skill functions like a self-contained SOP (workflow), bundled into a directory with a SKILL.md file that defines its metadata, name, description, and references to additional resources. This makes Skills composable and portable. Can’t say much about efficiency, yet. When Claude encounters a task, it scans available metadata to identify relevant skills and loads only the necessary files or code. This progressive disclosure design keeps the agent fast while maintaining deep specialization.
One of the problems that MCP and many other knowledge ingestion methods have when pushing knowledge into context is that they prepopulate the context (works as intended), but at the cost of context window saturation. This often leads to subpar conversations due to the lost-in-the-middle problem.

Since they are basically just flat files, Skills are much easier to maintain than having to run a full MCP server. On the other hand, you might end up with an unmaintainable collection of external files. Maybe the future is to compile them and distribute them like binaries. At its core, a Skill is structured as a directory that includes a central `SKILL.md` file. This file begins with a YAML frontmatter defining key metadata, such as the skill’s name and description, which serve as its primary identity attributes. When the agent starts up, it automatically preloads this metadata from all installed Skills into its system prompt, allowing it to recognize and reference them contextually.
This is an abbreviated example of a PDF manipulation skill showing little code bits that can be executed when needed.
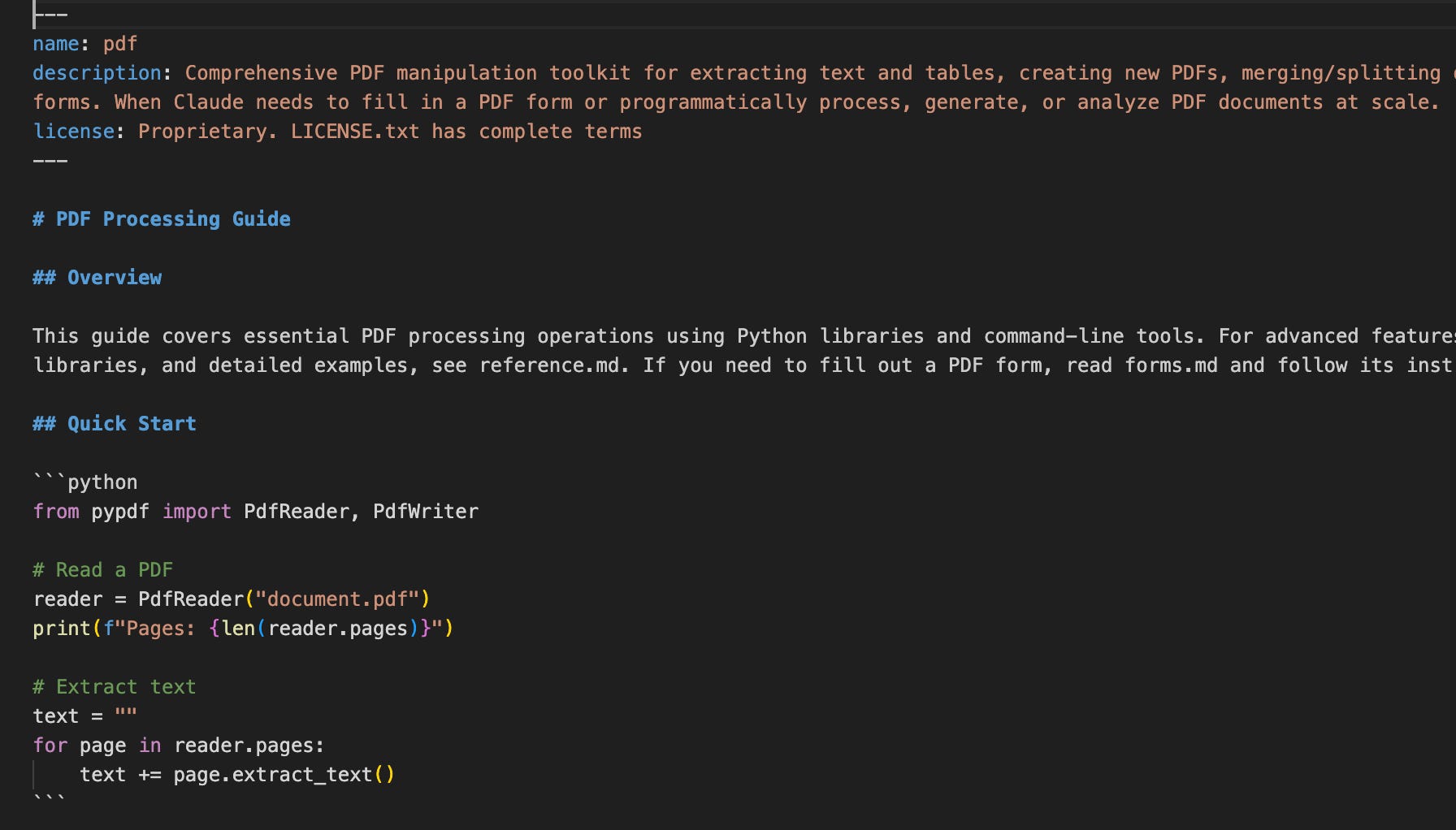
The most interesting feature of Skills is “progressive disclosure”. Skills embed just enough connective tissue into context to identify where to look to proceed without loading all of it into context.
Per Anthropic, one should be able to create own Skills and upload them as a Zip file into Claude. But at least my version doesn’t have this function.
Skills are a simple concept with a correspondingly simple format. I think this simplicity makes it much easier for devs like us to build customized agents and give them new capabilities. And in that, they remind me a lot of Agents.md.
AGENTS.md
Agents is an open-format file based on Markdown that can also be used to define and guide an agent’s operating instructions, build steps, code conventions, and test workflows, aimed at helping AI coding agents (and standardizing across tools) understand and engage with a repo effectively.
Claude Agent Skills is a vendor-specific modular format for the Claude agent ecosystem: folders containing “skill.md” files plus optional code/scripts/resources that Claude can autonomously load when relevant, enabling workflow specialization and code execution.
In contrast, AGENTS.md is an open-standard Markdown manifest designed initially for coding agents across tools: placed at the root of a repository, it gives build/test/style/PR instructions for AI coding assistants, but does not itself provide executable capability modules.
Claude Skills actively grants agents new abilities by adding executable, modular packages of code and procedural knowledge, like giving the agent new tools or expert workflows to run autonomously. Agents.md only defines behavioral guidelines and interaction standards that any agent can follow, improving coordination and consistency but not enabling new skills or actions.
Yes, but why does it matter?
Most LLMs, whether it be Claude, GPT, or Perplexity, can’t do much work completely unguided. So we are still far away from truly autonomous tasks. Even when I was building my News Explainer App, all the models made loads of mistakes. There was never a situation where the system was capable of understanding the change it changing all the artifacts selectively without just rewriting the whole thing.
When we want to build agents that actually matter and solve client problems, especially in the highly desired Enterprise category, then something has to change.
Maybe we have to start reframing the task and consider more effective problem/solution space explorations. And integrating SOPs might just to the trick.
So, how does it work?
Maybe we have to think about user experience differently? Why do we always have to start from a blank slate? In my mind, that triggers a new version of the cold-start problem.
Let’s start with a more structured approach.

Problem-Space Exploration
The problem-space exploration phase begins with a high-level problem statement and focuses on thoroughly understanding and defining the challenge before jumping to solutions. The AI agent has to play a crucial role in helping users explore different ways to frame their problem by soliciting alternative problem formulations and encouraging abstraction away from specific implementations. This divergent thinking phase involves asking clarifying questions and exploring the goals behind the request, allowing for a deeper understanding of what truly needs to be solved. For most professional workflows, this should already be well-known and can be pre-loaded. Then we can walk through the process using a convergent analysis to move from the broad, initial problem toward a specific, well-defined problem statement. This exploratory dialogue ensures that the actual problem, not just its surface symptoms, is properly identified and articulated before any code generation begins. If you don’t want just surface-level, you really need to dive deep into the problem the user wants to solve.
Solution-Space Exploration
Once a specific problem definition is established, the solution-space exploration phase begins by generating confirmed requirements and making implicit decisions explicit. Rather than immediately producing a single solution, our agent should encourage exploration of the solution space by suggesting alternative solution approaches and discussing their potential trade-offs. Think about it like tree-of-thought, graph reasoning, or other techniques. This divergent phase helps users consider different implementation strategies, architectural patterns, or algorithmic approaches that might address their needs. Through convergent analysis, these alternatives are evaluated and refined until reaching the final solution. The agent then produces the actual implementation. This methodical approach ensures that users don’t just get a solution, but rather an informed solution that considers multiple possibilities and makes conscious trade-offs based on the specific requirements and constraints of their problem.
Bringing it all together
The goal is to support program design processes by broadening the design space and exploring explicit strategies to overcome Human-LLM communication limits, helping users consider higher-level design objectives while tracking grounding explicitly to mitigate mismatched metaphors and expectations. Similar to AI Agents, users often face scattered attention; for example, clicking on something may trigger multiple information pop-ups or doom scrolling, making it unclear which is important and causing the mental model to be lost.
Hence I am pursuing a three-tiered model.
The Creator Model
The 3 Creator Model positions the User, UI/Design Interface, and Agent as a collaborative triad. The User contributes domain knowledge, goals, and creative intent, guiding high-level design decisions. The UI/Design Tool Interface when AI Agents are introduced: it shifts from a static interface to a more dynamic, agent-aware workspace that surfaces contextual suggestions, guides workflows, and tracks grounding between user intent and system output. Here, agent.md or Claude Skills act as structured connectors that define how the LLM can assist, encoding specific tasks, reasoning rules, or workflows, so that the agent can perform contextually relevant actions without constant user prompting. The LLM then functions as the reasoning engine, filling gaps, generating logic, and linking abstract concepts, while the user interprets outputs through the enriched UI. Together, this model creates a fluid loop where human creativity, interface guidance, and agent reasoning converge, expanding design possibilities and improving clarity in Human-AI collaboration.
At the core of this system are fundamental building blocks that cannot be altered: the user, the UI/design interface, and the LLM, but the power comes from finding new ways to combine them. This is where in-context learning plays a crucial role. Unlike traditional gradient descent, in-context learning is not an implicit adjustment of model weights; instead, the model adapts on the fly to complete patterns it observes, responding dynamically to examples provided in the current session. This creates an almost magical effect: the LLM can adjust its reasoning, anticipate user intent, and fill in gaps in real time, enabling novel workflows and design strategies without ever modifying the underlying architecture. And I am not sure if I want to hand over all that power to a UI that I can’t control. Open-source should guide this.
Sorry, this post got long.
In Closing
Many companies are exploring Agentic UI, raising the question of how such interfaces help us organize our work and thoughts, a question that may lie at the heart of this post: should we favor specific-purpose or general-purpose UI, and which is ultimately better? What I appreciate about Agent.md and Skills.md is their simplicity; anyone familiar with tech will recognize echoes of flat files or configuration files, though this simplicity also prompts questions about scalability in multi-agent environments that go beyond a single personal computer.
The naive approach to generative AI often follows an Ask→Solution pattern, but this assumes we already know what to ask.
In reality, discovering solutions frequently requires iterative exploration and insight gathering, and there is rarely a single “best” answer. That’s why I think that standard browser solutions might actually be a misstep. Yes, of course, we all know how to navigate them easily. But what if the software development worked with you and adjusted the user experience every time? In this context, reasoning acts as the prefrontal cortex, guiding thoughtful decisions, while tools like Amigula tap into more instinctive or emotional aspects, highlighting the complementary interplay between logic and intuition in complex problem solving.
In the end, the future of Agentic User Experience will likely not be defined by a single interface or platform, even though Anthropic seems to be a couple of steps ahead. But judging by how seamlessly humans, agents, and tools can co-reason within shared contexts, whether it be through Atlas, Comet, or Claude Skills, the goal remains the same: to move beyond chat-based exchanges toward structured, transparent collaboration where intent, reasoning, and execution align fluidly.
The real challenge, and opportunity, lies in designing interfaces that let us think with our agents, not just at them, creating a new cognitive layer that augments how we explore, decide, and build.
Hopefully, we will reach that point without handing over all our privacy.
For the time being, I uninstalled Atlas.

Here are some of my favorite Claude Skills links
Anthropic’s Github: https://github.com/anthropics/skills/tree/main
Superpowers https://github.com/obra/superpowers