
The Ultimate Guide to Visual Language Action Models (VLAM)
Can AI truly understand the physical world? Physical Reasoning from Video.

For the last quarter of a century, we have developed AI solutions for low-risk environments like recommendation engines, content moderation, or ad-targeting. These systems perform well in constrained digital environments, where errors remain contained and carry minimal cost. Deploying in the physical world is substantially more complex, as mistakes propagate into real systems, producing safety, reliability, and operational risks. And if we want to conquer space and the ocean floor, we need to develop this capability for all of humanity.
Recently, we have seen physical AI models misbehaving when interacting with the real world.
Industrial Humanoid Robot (Unitree H1) Goes Berserk During Testing in China
Tesla’s Robotaxi Going Rogue in Austin.
The US Navy’s Autonomous Drone program faces setbacks.
As companies like Pony.ai expand around the world, and new entrants like Tensor Auto start building robot-taxis, the stakes are only ever increasing. The challenge these companies face, teaching artificial intelligence human-like real-world intuition, has long been a barrier in developing and especially scaling robotics and autonomous systems. Training robots has suffered from an inability to generalize for a very long time. And while there has been some progress (TRI, X-Embodiments), replicating the nuanced understanding we humans have of physical interactions, object permanence, gravity, or friction, remains unmatched.
But this might all change now. Because NVIDIA’s Cosmos Reason1-7B just topped Huggingface’s physical reasoning leaderboard. Benchmark scores confirm a strong performance: An average score of 65.7 across key robotics and autonomous vehicle tasks. Although we should consume such benchmarks with a pinch of salt.
Let’s dive into the fantastic world of Vision-Language-Action models.
Table of Contents
Architectures of Physical AI
Challenges of Physical AI
Visual Language Action Models in general
NVIDIA’s Cosmos World Foundation Model (WFM)
NVIDIA’s Cosmos-Reason1,
Meta’s Vision Language World Model,
Wayvve’s Lingo-2, and
EO Robotics EmbodiedOneVision
Architectures of Physical AI
It’s nothing new that by now, large language models are really good at processing text. Some even display impressive multi-modal processing capabilities. I.e., you can upload an image into ChatGPT and it will actually “understand” it.
But that does not mean that these models are capable of translating words into physical actions. A more sophisticated architecture is needed for this.
So, before we dive into VLA models, I will outline more explicitly how the architecture for building Physical AI systems works and what challenges this brings along with it. Then I will dive into the most recent models and papers published.
We begin, similar to my traditional autonomous agents definition, with sensors.
Sensor Layer
Sensors form the foundation of this architecture as Physical AI relies on multiple sensor modalities to gather comprehensive environmental data. Multiple cameras provide visual information for object recognition and scene understanding from different angles. Although Tesla got rid of them, I still believe in Radar and LIDAR. Radar offers reliable distance and velocity measurements in various weather conditions, while LiDAR generates 3D point clouds for spatial mapping. Other sensors include GPS provides global positioning data, inertial measurement units, or ultrasonic sensors. This multi-sensor approach unlocks redundancy and delivers robustness in data collection
Perception layer
In the perception layer, the raw sensor data is processed into meaningful interpretations of the driving environment using specialized perception models and sensor fusion algorithms.
In traditional autonomous systems, we may deploy the following standard models:
Specialized perception models are task-specific algorithms where lane detection uses techniques like Hough transforms or deep learning to identify road boundaries and lane markings, traffic light detection employs convolutional neural networks to recognize signal states and timing, and traffic sign detection interprets regulatory and warning signs through trained classification models. Object detection & tracking identifies and monitors vehicles, pedestrians, and obstacles using models like YOLO or R-CNN variants, providing real-time recognition capabilities. Free space detection determines drivable areas through semantic segmentation or point cloud processing algorithms.
Sensor fusion models like Kalman filters and Extended Information filters combine a variety of sensor data with high-density maps to precisely determine the vehicle's position within the mapped environment, creating a more robust understanding than any single sensor could provide alone.
Planning layer
But autonomous driving is not only about understanding the “now”. Using the interpreted environmental data, we still need to know where we are going.
Thus,
Route planning for determining the optimal path to the destination.
Prediction algorithms for forecasting of the future behavior of other road users.
Behavior planning for deciding high-level maneuvers like lane changes or turns.
and finally
Trajectory planning for calculating the specific path and speed profile the vehicle should follow, considering safety constraints and traffic rules.
And especially, trajectory planning is where VLAMs shine. But I am getting ahead of myself.
Control Layer
The fourth and final stage translates planned trajectories into actual vehicle motion. PID controllers manage basic control loops for steering, throttle, and braking. Model predictive control provides more sophisticated control algorithms that anticipate future states. Other control systems may include stability control, traction management, or specialized actuator control systems that physically execute the planned maneuvers through the vehicle's mechanical systems.
Challenges of Physical AI
We don’t have easily scalable and trainable autonomous vehicles yet. Just an observation. We humans are incredibly good at judging driving situations we have not encountered yet. But that is also a function of age. There is a reason why we don’t let kids drive (besides their obvious height constraints).

Problem 1: Edge cases are incredibly valuable.
Data on edge cases is incredibly difficult and expensive to acquire. The more rare the event, the more likely it is that the system might misbehave and cause physical harm. And as we can see with the fleet of Google Street Map cars, physical data is costly to collect, curate, and label.
Problem 2: The real world is a spatial and temporal environment bound by the laws of physics.
Spatial data is also a hard problem because the environment in a spatial 3D environment has objects have different shapes, sizes, and distances, while the car’s sensors might perceive them in 2D as the same. They also have to comply with basic rules of physics. Reconciling multi-camera input makes this also more complex. And then a lot of what we observe is constantly moving. Either as we pass along houses or factory floors. Or they move themselves, like pedestrians, vehicles, or drones. Therefore, decisions can’t be just about “where things are now” but “where they will be in the next second, 5 seconds, or 30 seconds.” On top, prediction errors compound quickly, making safe planning even more difficult.
Problem 3: Output modality needs to be incredibly accurate.
Even when perception and predictions are accurate in a volatile environment, the system must translate that understanding into actions. I.e., steering, braking, accelerating, grasping, or rerouting, each with different latency, precision, and safety requirements. The importance of high-quality output modality is as critical as getting the input right.
Problem 4: Trust & explainability in decision-making.
Humans can explain their decisions with natural language. But to have one human describe the actions of another human leads to no trust in the explanation. There is a reason my moderators at sports events are largely for entertainment. This is known as the back-seat driver problem: when one agent tries to explain the decisions of another, the explanation rarely inspires trust.
Btw., this also outlines the importance of agency in agentic decision making.
Visual Language Action Models
Visual Language Action Models (VLAMs) are AI systems that integrate visual perception, natural language understanding, and action planning to enable agents to interpret their environment, follow language instructions, and perform corresponding actions.
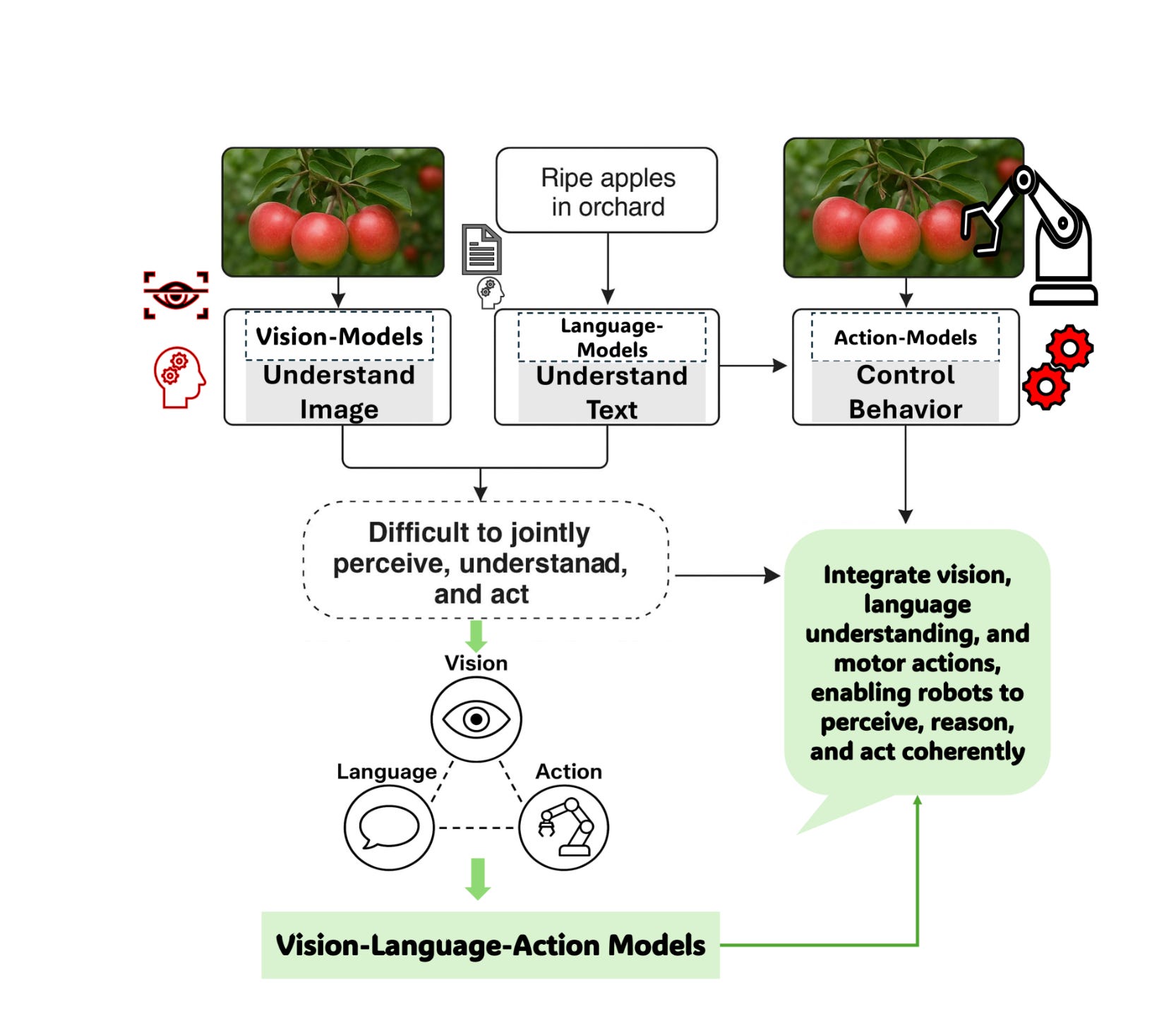
The benefit of integrating VLAMs into physical AI architectures is that it allows the system to not only perceive its environment but also interpret complex scenarios, make contextual decisions, and potentially communicate its intentions—capabilities that mirror human-like driving behavior. Cosmos can generate photorealistic, physically based, synthetic data.
Traditional autonomous systems have relied on sensor fusion and rule-based decision-making. The use-cases for VLAM are different:
Data curation & annotation: To reduce cost and increase quality, we need to automate high-quality dataset curation and annotation. VLAMs can interpret raw multimodal inputs, generate candidate labels, and validate them against schema constraints, reducing reliance on manual annotation.
Robot planning & reasoning: Planning and reasoning can guide deliberate, methodical decision-making with vision language action (VLA) models. VLAMs unify perception and instruction-following to translate natural language goals into structured action plans that remain robust under real-world uncertainty.
Video analytics AI agents: Extract actionable insights and perform root-cause analysis on massive video datasets. VLAMs integrate visual understanding with temporal reasoning and language-based explanation, enabling both anomaly detection and human-readable causal narratives.
The advancement here lies in the system's ability to understand nuanced real-world situations through language, with the goal of improving how vehicles handle unpredictable real-world conditions. For the transportation & logistics industry, this will be a revolution. But for us normal mortals, it means safer and more reliable autonomous vehicles.
We begin with:
NVIDIA’s Cosmos World Foundation Model (WFM)
A couple of months ago, right after CES, I already touched on NVIDIA’s Cosmos World Foundation Model (WFM). I hold the belief that synthetic trajectory data is an important step towards the generalization of autonomous movement. WFM builds on this concept by establishing a pre-trained (“vanilla”) model, not unlike traditional LLMs, trained on Internet-scale datasets providing broad time-frozen knowledge across many environments and tasks. However, to perform well in a specific real-world application, such as accurately guiding a robot on a factory floor or safely navigating an autonomous vehicle through traffic, general capability is not good enough. We must fine-tune them in post-training on a smaller, targeted dataset collected from their particular environments.
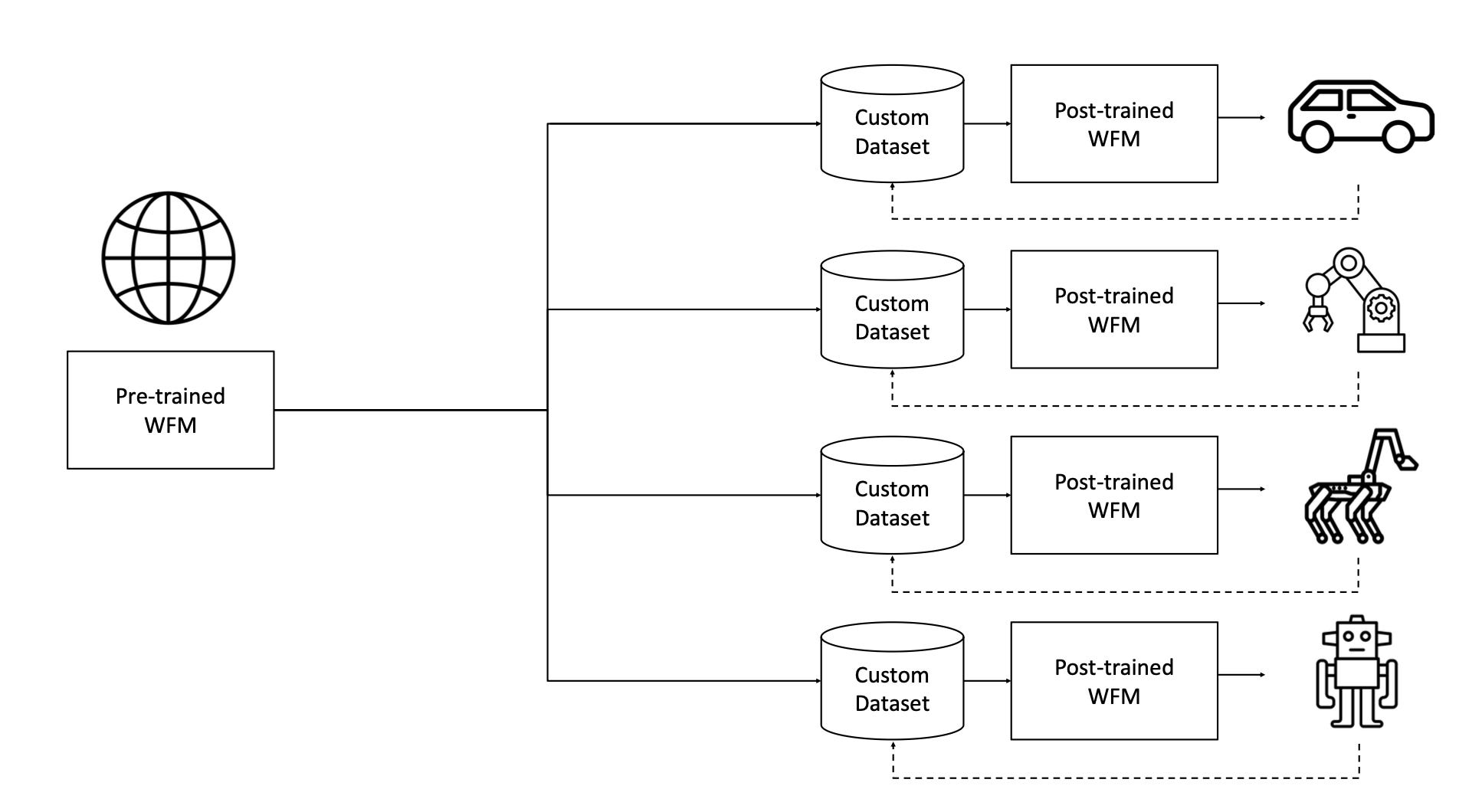
This process produces a post-trained, specialized WFM: a model that retains the broad capabilities of its foundation training while being adapted to go deep into a specific Physical AI use-case. WMF in its current (Fall 2025) iteration has evolved into a suite of open, physics-aware generative AI models, including diffusion and autoregressive transformer architectures, designed to simulate and predict future states of virtual environments (via video) from inputs like text, images, or past frames.
These language models may also augment vehicle-to-infrastructure communication, enabling more efficient traffic management and coordinated mobility systems.

Within WMF, there are specialized models. Cosmos-Reason1 is one of them.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
NVIDIA's Cosmos Reason1-7B model aims to be an evolution in the domain of Physical AI through embodied reasoning. Embodied reasoning refers to the ability of an AI or robotic system to ground its reasoning and decision-making in a physical context, using sensory input and interactions with the environment. So, instead of abstract reasoning alone, it integrates perception, action, and feedback to plan and adapt in real-world settings.
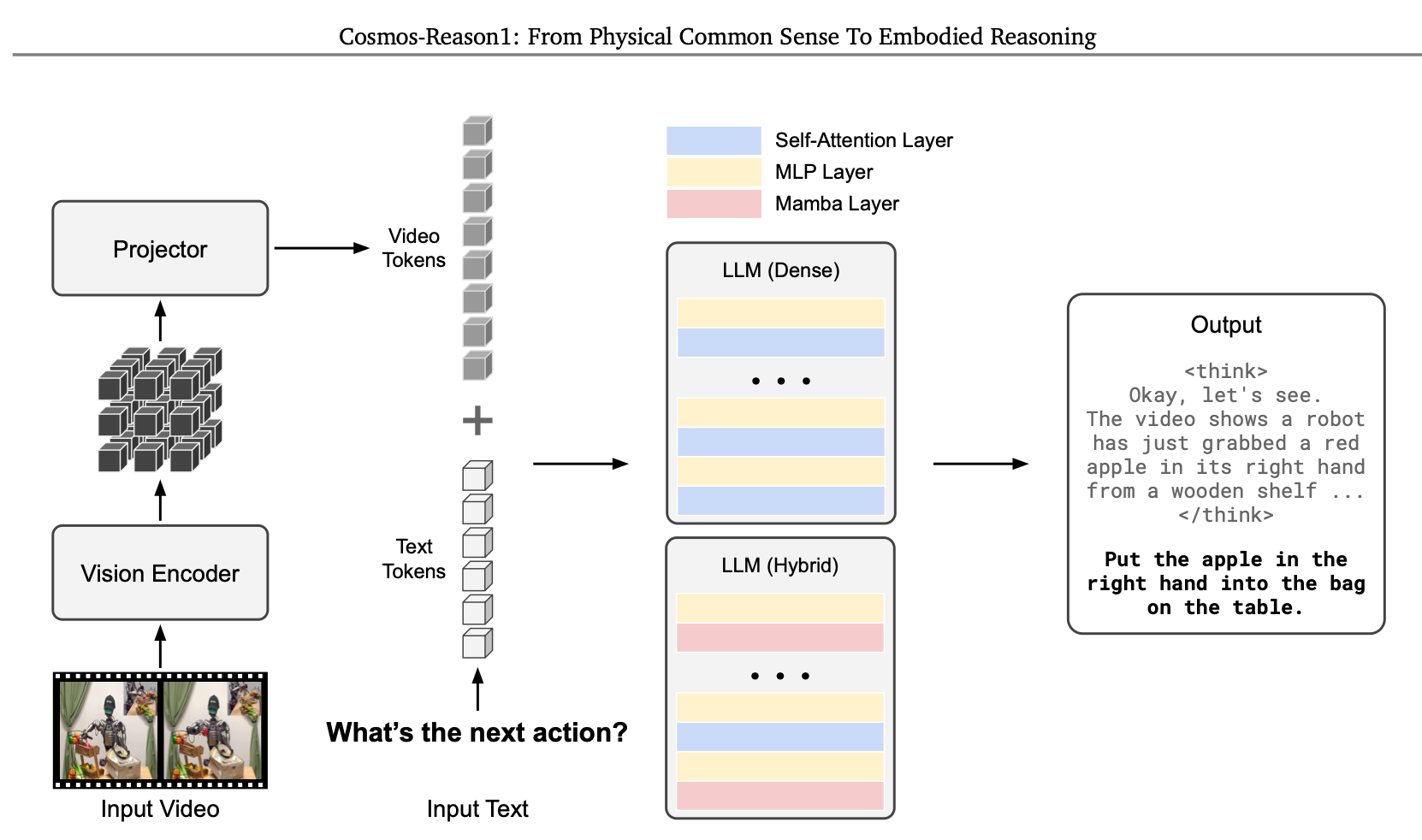
Cosmos-Reason1 employs a multimodal decoder-only architecture similar to LLaVA, available in two model sizes: Cosmos-Reason1-7B and Cosmos-Reason1-56B. The architecture follows a sequential pipeline where the input video is processed through a vision encoder, then a projector that aligns visual tokens with text embeddings, before being fed into the LLM backbone. The larger 56B model incorporates a hybrid Mamba-MLP-Transformer architecture to improve efficiency in handling long sequences, combining the linear-time complexity benefits of Mamba's selective state space models with Transformer layers for comprehensive long-context modeling.
On a simple step-by-step workflow basis, Cosmos-Reason1 works like this:
It accepts the video input,
It converts video into an understandable format, and then
It tries to reason about it through long chain-of-thought thinking processes before generating a response in language space.
This response will be returned in natural language and includes both explanatory insights and but also embodied decisions (pose, trajectory, etc). In my opinion, what makes Cosmos Reason1 unique compared with traditional VLMs is its ability to infer and reason using physical common-sense knowledge.
So what’s the magic here?
Statistical models have no true “understanding” of the world they exist in. Humans and animals acquire a physical common sense through passive observation of the world around us. For example, infants can understand basic concepts such as object permanence and gravity already in a few months after birth. To develop this understanding computationally, models must be trained on expensive human-annotated datasets that capture object interactions, spatial relationships, and causal dynamics, enabling them to learn predictive patterns about how objects behave in three-dimensional space through labeled examples of physical phenomena.
However, unlike passive understanding, reasoning in embodied AI must be grounded in action. I.e., reasoning emerges through the coupling of perception and control layers, where the system learns by acting on the environment, observing outcomes, and adjusting its internal models accordingly.
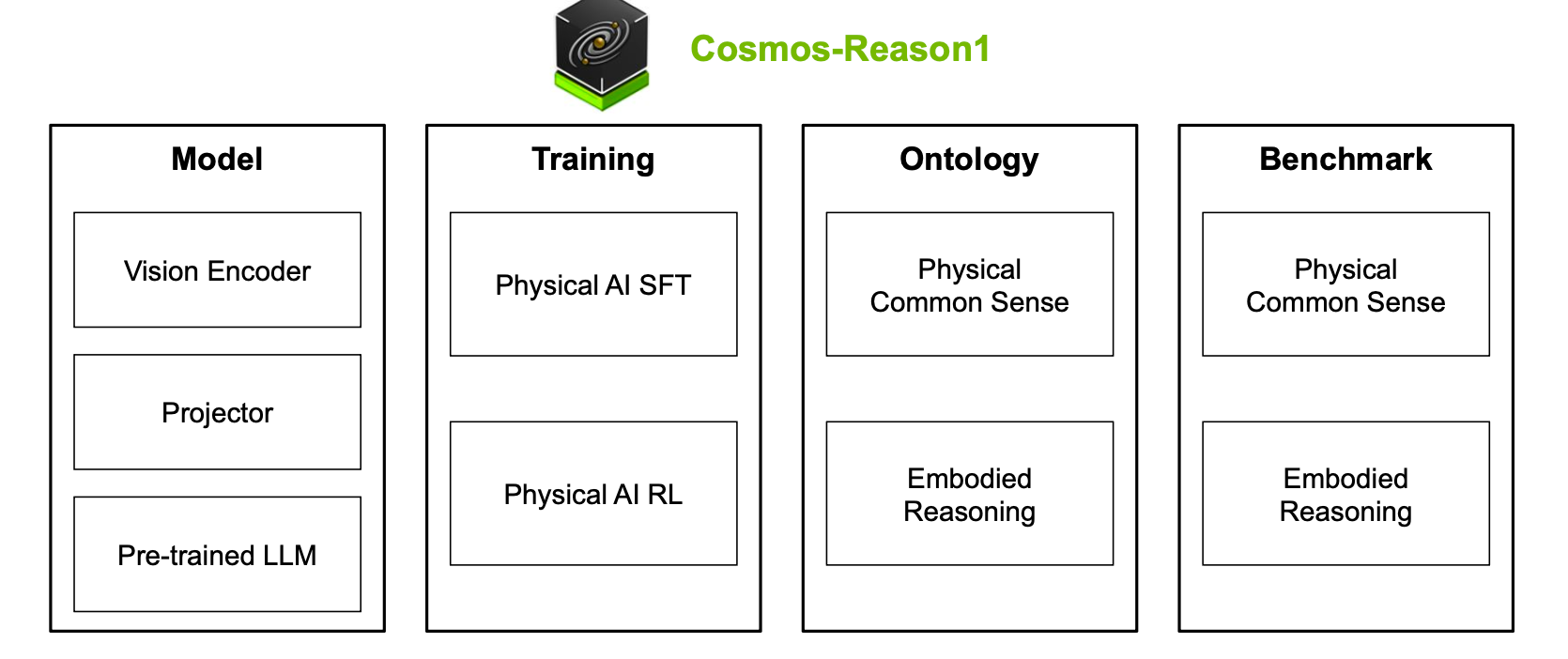
As the real world is temporal, spatial, and bound by the laws of physics (Problem 2), Reason1’s “common sense” is grounded on an ontology of three main categories.
As shown in the image below.
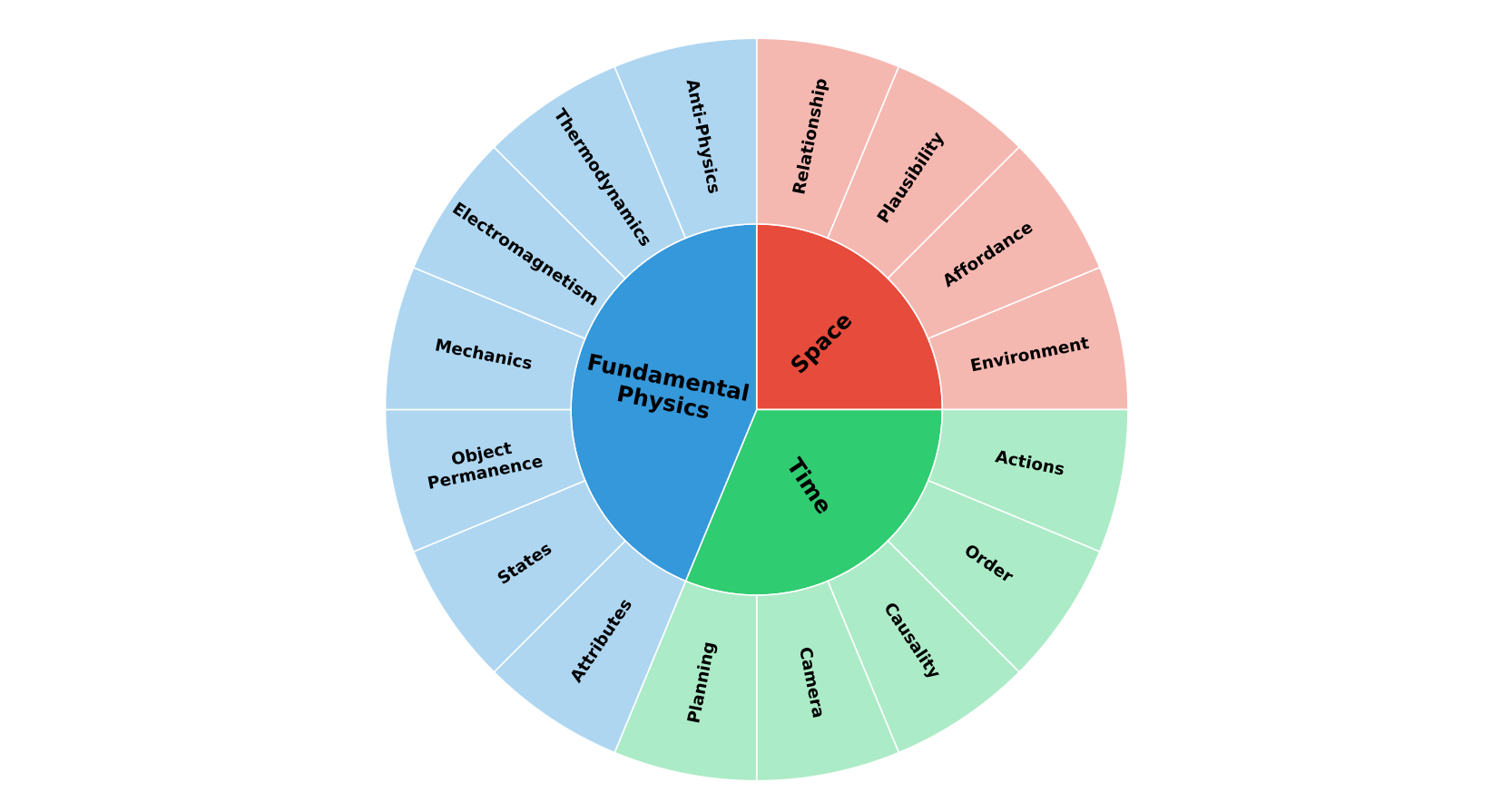
This shall enable the model, and the robots it steers by extension, to not only comprehend what they currently observe but also to plan intelligently ahead.
But there is more to it.
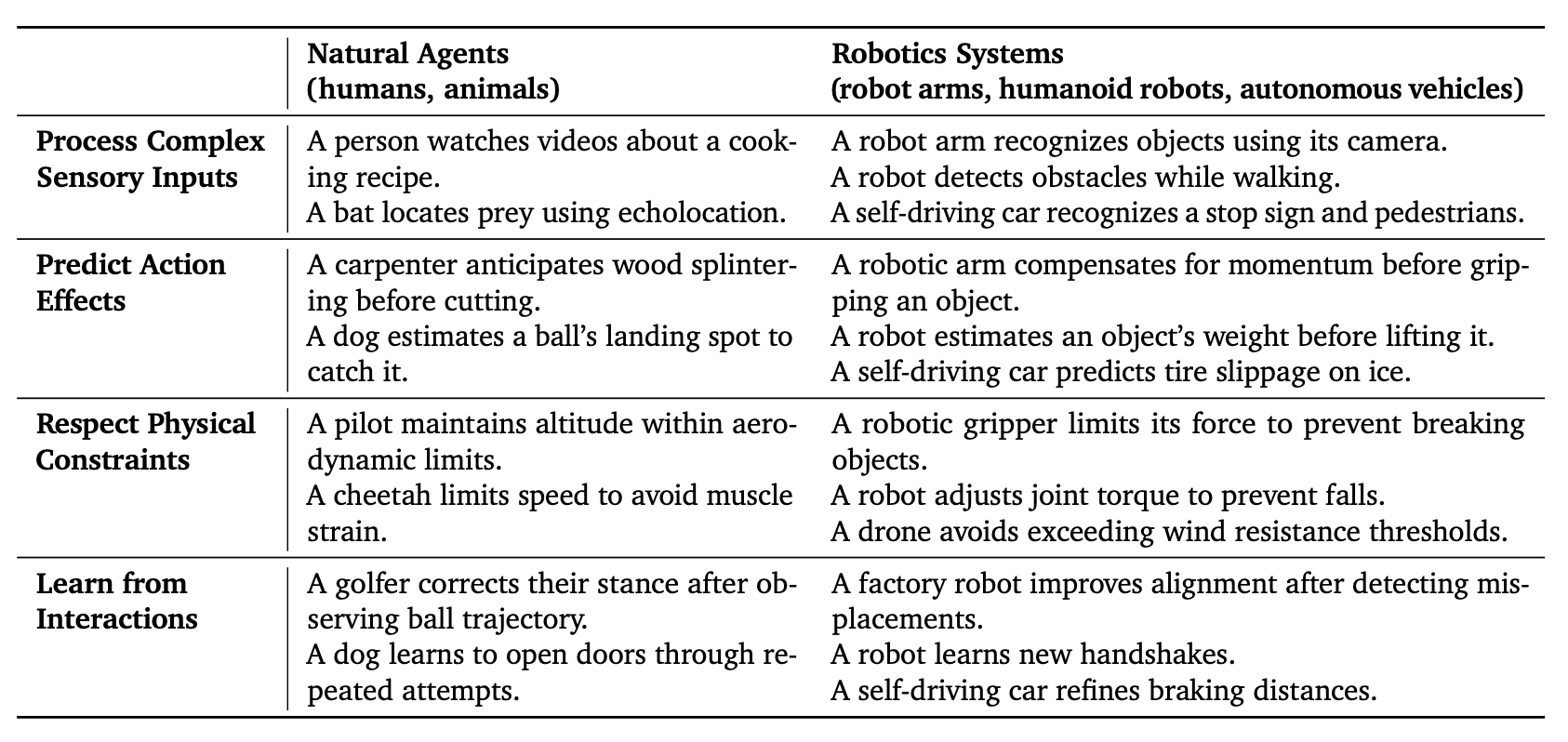
Specifically, reasoning in physical space requires the capability to:
Process complex sensory inputs. Unlike symbolic reasoning that relies on clean, structured data, embodied reasoning must parse noisy, partial, and ambiguous multimodal signals to extract reliable patterns for decision-making.
Predict action effects. Every action alters the environment, so embodied reasoning requires an internal model of cause-and-effect. E.g., how objects respond to force, how a robot’s kinematics interact with terrain, or how vehicle dynamics shift under changing conditions.
Respect physical constraints. Beyond abstract optimization, embodied reasoning must respect real-world physics, inertia, friction, and material limits while producing long-horizon plans that are both safe and efficient in execution.
Learn from interaction. Actions generate feedback loops, and embodied reasoning depends on integrating this feedback to refine policies over time, enabling continuous improvement and dynamic adaptation to changing environments.
Here are some examples from the paper.
Cosmos-Reason1 introduces several key innovations for the advancement of physical AI reasoning capabilities. The system establishes hierarchical physical reasoning ontologies that systematically organize capabilities across space, time, and fundamental physics domains, providing a structured framework for understanding and evaluating physical common sense.
It incorporates self-supervised intuitive physics tasks such as spatial puzzles, arrow-of-time detection, and object permanence testing that are both scalable to generate and verifiable through rule-based rewards. The framework enables cross-embodiment reasoning by applying unified reasoning principles across diverse physical agents, including humans, robotic arms, humanoid robots, and autonomous vehicles.
And finally, the system features a novel asynchronous reinforcement learning infrastructure with fault tolerance and dynamic scaling capabilities, achieving approximately 160% improvement in training efficiency compared to traditional colocated frameworks while maintaining robustness through automated recovery and resource management.
Meta’s Vision Language World Model
Meta’s Vision Language World Model (VLWM) is designed to enable AI agents to plan and reason about actions using natural video inputs. “World model” facilitates this by allowing agents to internally optimize action plans, reducing the reliance on exhaustive trial-and-error in real environments.
Given a video, VLWM aims to extract a structured language representation consisting of two key components:
Goal: A description and interpretation of the desired outcome.
Procedural Plan: An action-state sequence outlining the steps to achieve the goal.
For such a video-to-text extraction task, a straightforward approach might involve providing a Vision-Language Model (VLM) with the full video and prompting it to extract these language representations. However, this approach encounters the "impossible triangle": achieving high spatial resolution for fine-grained perception, maintaining a long temporal horizon that spans many procedural steps, and utilizing a large and intelligent VLM capable of following complex instructions.
To address this challenge, VLWM employs a two-stage strategy:
1. Compression into a Dense Tree of Captions: The input video is compressed into a dense Tree of Captions, significantly reducing data volume while preserving essential semantic information.
2. Extraction of Structured Goal-Plan Representations: Structured goal-plan representations are extracted from these captions using large language models (LLMs). Since this stage operates purely on text, it enables efficient processing with large LLMs and allows for iterative quality refinement through Self-Refine techniques.
This approach enhances the efficiency of video understanding and sets a new standard in AI's capability to plan and reason based on visual data.
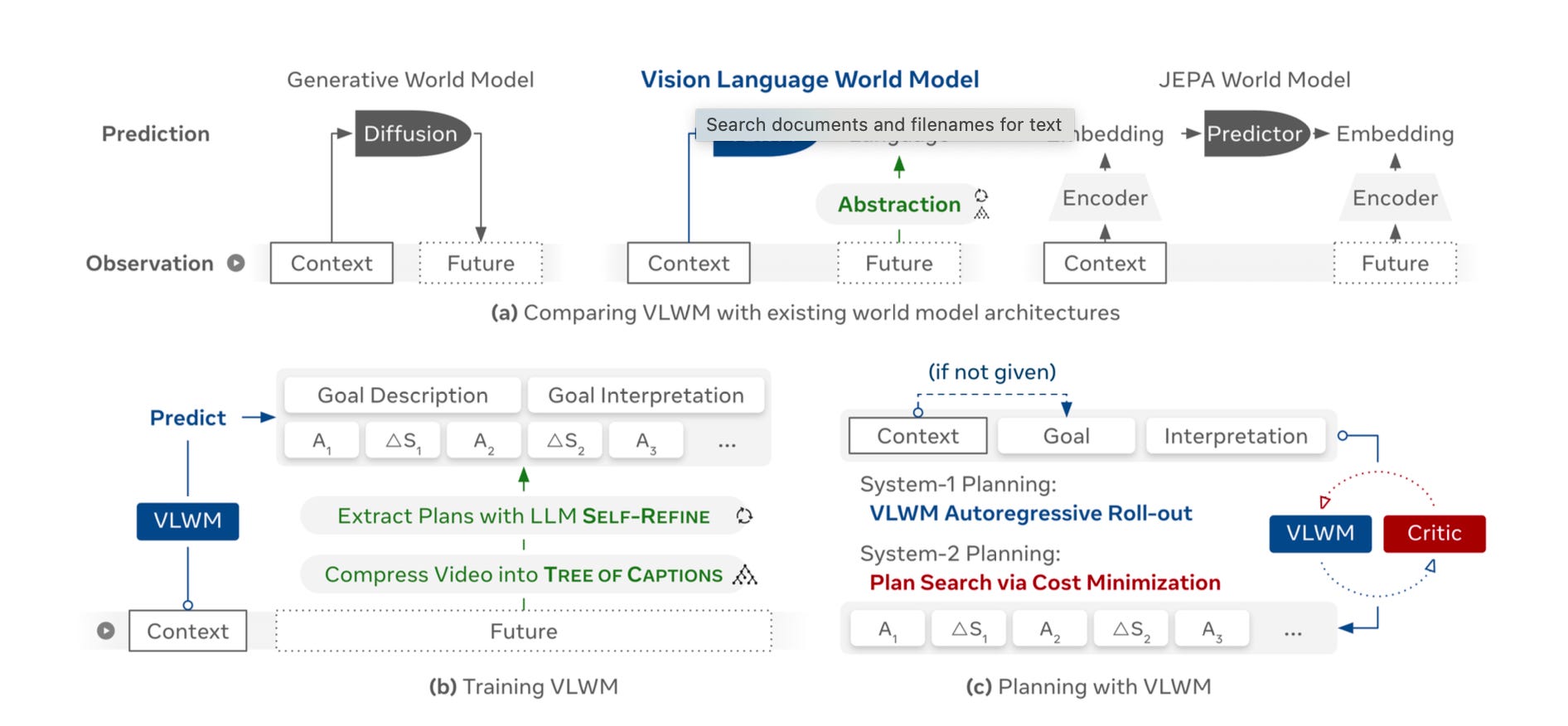
What makes VLWM unique is its dual-mode planning system that mirrors the psychological distinction between fast, intuitive thinking and slow, deliberative reasoning. Reminds me of HRM.
System-1 Planning operates as the model's reactive mode, generating plans through direct autoregressive text completion. When presented with visual context and a goal description, VLWM first interprets the goal by predicting both the initial world state ("Now, the kitchen is set up with necessary ingredients...") and the expected final state needed for achievement ("To achieve the goal, the eggs need to be cooked and mixed with tomatoes..."). The model then generates an interleaved sequence of actions and world state changes in a single forward pass, where each action, like "Crack eggs into a bowl and whisk them together," is immediately followed by detailed descriptions of environmental transformations. These world state descriptions function as internal reasoning chains that help track task progress, but the autoregressive nature creates a critical limitation—once an action token is generated, it becomes irreversible, potentially leading to error accumulation in complex scenarios.
System-2 Planning addresses these limitations by introducing reflective reasoning through internal trial-and-error with the learned world model. Instead of committing to a single action sequence, System-2 generates multiple candidate plans and uses VLWM to simulate their effects, predicting the resulting world states for each possibility. A separately trained critic module—a 1B parameter language model—evaluates the semantic distance between these predicted outcomes and the desired goal state, assigning costs that reflect how well each candidate plan advances toward the objective. The system then selects the action sequence with the lowest predicted cost, effectively performing reasoning by searching through the space of possible futures. This critic is trained through self-supervised learning using ranking constraints that teach it to assign lower costs to meaningful progress and higher costs to irrelevant or procedurally incorrect actions, enabling the model to optimize plans without requiring explicit reward annotations.
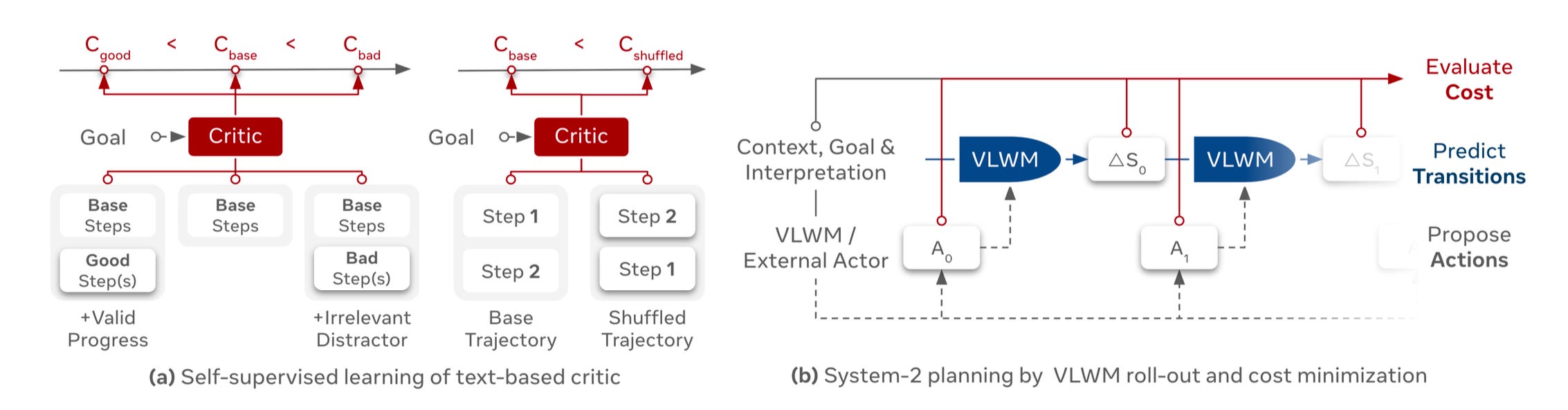
First, it constructs training samples by taking base partial trajectories and appending either valid next steps from coherent task continuations or distractor steps sampled from unrelated tasks, training the model to satisfy ranking constraints where valid continuations receive lower costs than irrelevant additions. Second, it generates negative samples by randomly shuffling steps in base trajectories, teaching the critic to assign higher costs to procedurally incorrect sequences and ensuring sensitivity to temporal coherence. This dual approach enables the critic to distinguish meaningful progress from both irrelevant distractors and temporally disordered actions. The architecture benefits from VLWM's video-text formulation, which allows initialization from pretrained vision-language models like PerceptionLM-8B, inheriting strong visual perception capabilities along with language understanding and commonsense knowledge from large language models, while the language-based world state representation provides computational efficiency and interpretability compared to pixel-based generative approaches.
Wayvve’s Lingo-2 - A closed-loop Vision-Language-Action-Mode
Wayve's LINGO-2 is a closed-loop Vision-Language-Action Model (VLAM) that integrates visual perception, natural language processing, and driving control to provide real-time explanations of autonomous driving decisions. Unlike its predecessor, LINGO-1, which operated as an open-loop system offering commentary without influencing vehicle behavior, LINGO-2 combines vision and language inputs to generate both driving actions and explanatory text. This integration allows the model to adapt its behavior based on natural language prompts and provide continuous commentary on its decision-making process, enhancing transparency and trust in autonomous driving systems.
The architecture of LINGO-2 comprises two primary components: a vision model and an auto-regressive language model. The vision model processes sequences of camera images into tokens, which, along with additional contextual information such as route, speed, and speed limits, are fed into the language model. The language model then predicts both a driving trajectory and corresponding commentary text. The vehicle's controller executes the predicted trajectory, enabling real-time interaction and adaptation to dynamic driving scenarios.
A distinctive feature of LINGO-2 is its ability to respond to natural language instructions and queries during operation. For instance, passengers can ask the system about traffic light statuses or request specific maneuvers, and LINGO-2 will adjust its actions accordingly while providing explanations for its decisions. This closed-loop interaction between vision, language, and action represents a significant advancement in autonomous driving technology, offering a more intuitive and interpretable interface for users.
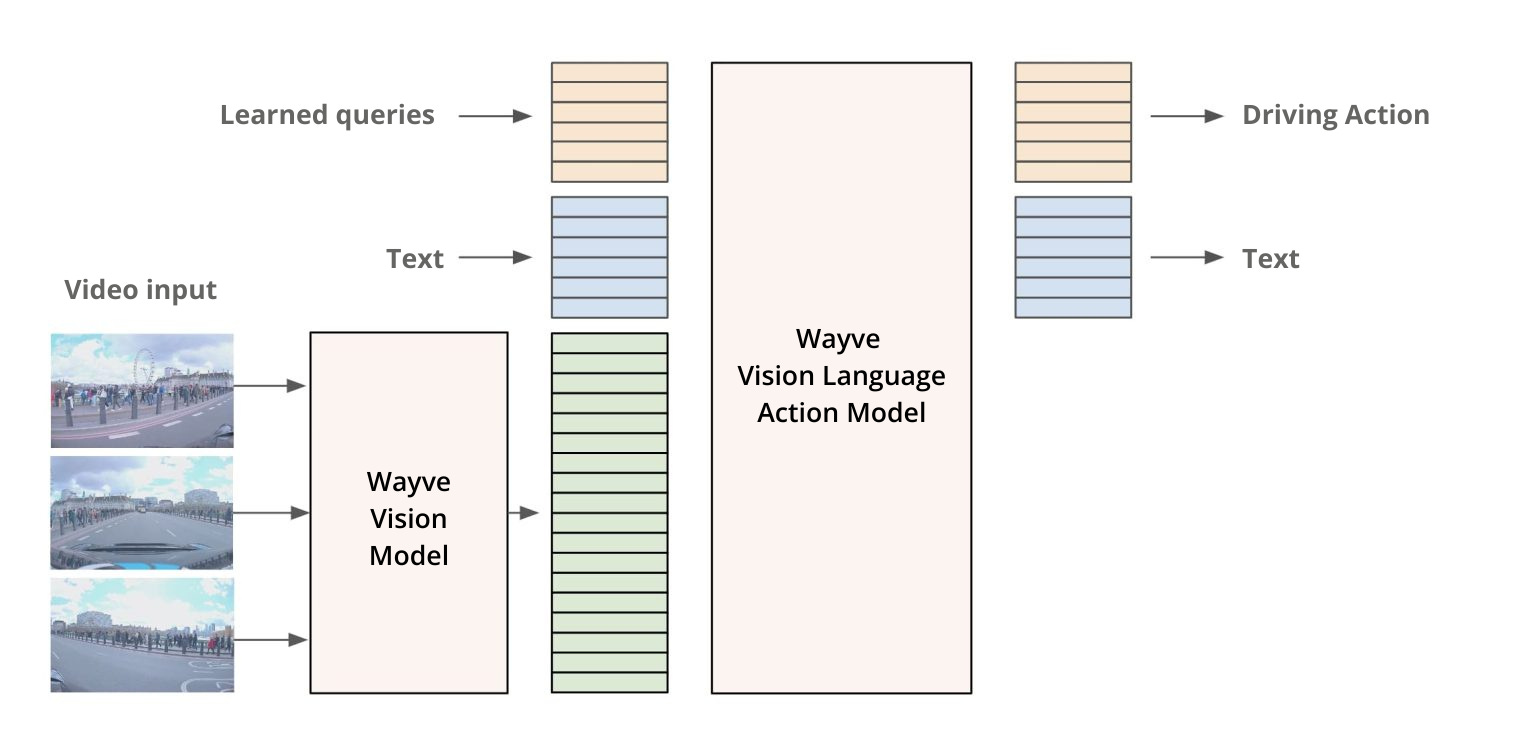
How does LINGO-2 work?
LINGO-2 “Driving with language” integrates vision, language, and action into a unified framework. It comprises two primary modules: a vision model that processes camera images of consecutive timestamps into a sequence of tokens, and an auto-regressive language model that predicts a driving trajectory and generates commentary text. These components work in tandem to enable real-time interaction between the vehicle and its environment, facilitating both driving behavior and explanatory dialogue.
The integration of language and driving behavior in LINGO-2 introduces several capabilities that enhance human-vehicle interaction and trust in autonomous systems. Passengers may, in the future, issue natural language commands, such as "turn right" or "find a parking spot," prompting the vehicle to adapt its behavior accordingly. Although the latter example is more likely than the former. Additionally, the system can provide real-time debugging explanations of its driving decisions, answering questions like "Why did you slow down?" or "What is the current speed limit?". This is incredibly important if you need to understand how these systems make decisions.
This approach enables easier testing in synthetic environments where identical scenarios can be evaluated with different linguistic instructions, providing unprecedented insights into AI behavior and decision-making processes
EO Robotics EmbodiedOneVision
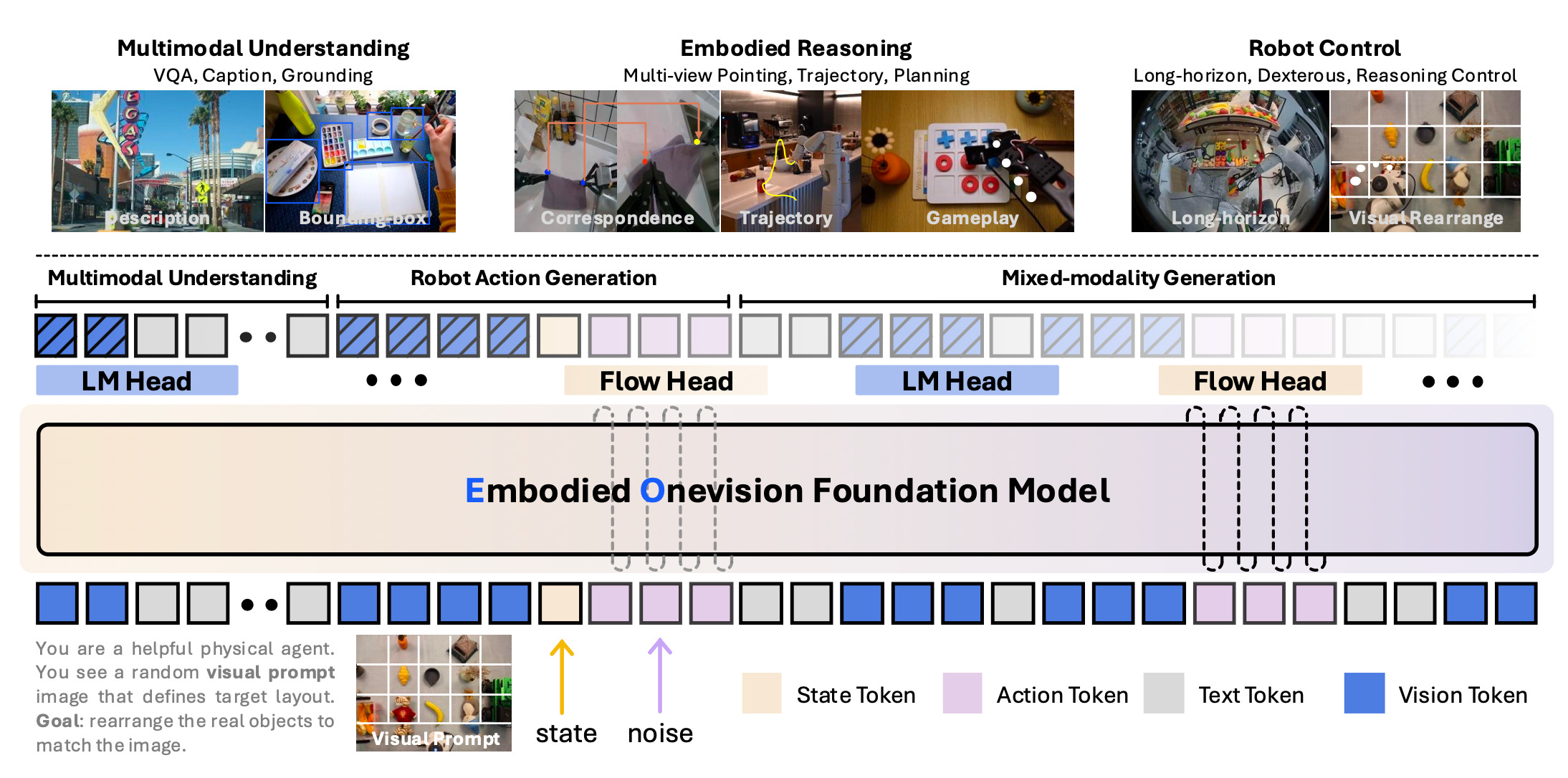
EmbodiedOneVision (EO-1), a unified embodied foundation model paired with the large-scale EO-Data1.5M dataset. Together, they represent a significant step toward building generalist embodied agents capable of understanding, reasoning, and acting across diverse environments. Unlike prior work that treats perception, reasoning, and control as loosely connected modules, EO-1 is also designed as a closed-loop system where vision, language, and action are interleaved during pretraining. This approach enables the model to predict actions in context, respond to language prompts, and reason about spatial and temporal dynamics within real-world tasks.
The system is motivated by advances in multimodal foundation models, which have shown that joint training across modalities yields superior generalization and reasoning. EO-Robotics extends these ideas into the embodied domain, emphasizing how robots can learn not only from static vision–language corpora but also from temporally grounded interaction data. With its unified model architecture, carefully curated dataset, and principled evaluation benchmark, EO-Robotics provides a foundation for the next generation of embodied intelligence research.
Architecture
At the core of EO-Robotics lies EO-1, a decoder-only transformer with approximately three billion parameters. The model integrates multiple modalities into a single shared representation space, handling images, video frames, text, and robotic actions without requiring separate specialized modules. This design departs from earlier Vision-Language-Action (VLA) model approaches that introduce action-specific heads or auxiliary training objectives.
EO-1 employs two complementary training mechanisms:
Auto-regressive decoding for discrete modalities such as text and symbolic tokens.
Flow-matching denoising for continuous robotic action trajectories.
Both mechanisms are unified through causal attention over the entire multimodal sequence, enabling EO-1 to capture dependencies between perception, reasoning, and action. The architecture is initialized with a pre-trained vision–language backbone, giving it broad perceptual and linguistic priors, and then adapted to the embodied domain by training on EO-Data1.5M.
To bridge action and non-action modalities, EO-1 incorporates lightweight multilayer perceptrons (MLPs) that encode and decode continuous motor actions into the tokenized sequence. This avoids retraining large action-specific modules from scratch, improving efficiency and enhancing cross-modal transfer. By aligning text, vision, and action tokens in the same autoregressive stream, EO-1 treats reasoning and acting as a single process rather than separate stages, resulting in more coherent robotic control.
Capabilities
EO-1’s abilities stem from both its architectural design and its large-scale training data. EO-Data1.5M provides over 1.5 million multimodal samples, interleaving vision, text, and robot actions. The dataset combines two key sources:
Web-based vision–language corpora, which provide general visual-linguistic grounding.
Real-world robot episodes supply action-level continuity, spatial grounding, and temporal structure.
A custom data pipeline ensures diversity, quality, and task coverage. Robot videos are filtered and clustered to reduce redundancy, split into subtasks, and captioned by both pretrained vision–language models (VLMs) and human annotators. From these subtasks, question–answer pairs are generated to probe temporal and spatial reasoning. Human annotators refine answers to ensure correctness, and the resulting interleaved sequences integrate visual tokens, linguistic reasoning, and motor actions.
Through this training regime, EO-1 acquires capabilities in several areas:
Spatial understanding: object localization, multi-view correspondence, and trajectory reasoning.
Task reasoning: planning sequences of actions and evaluating task progress.
Physical commonsense: reasoning about forces, constraints, and counterfactual outcomes.
State estimation: assessing object states such as open/closed or full/empty, and predicting the results of actions.
Performance is measured through EO-Bench, a benchmark constructed to avoid the pitfalls of conflated evaluation tasks. EO-Bench includes 648 QA pairs across four categories—spatial understanding, physical commonsense, task reasoning, and state estimation—allowing precise measurement of strengths and weaknesses. Unlike other benchmarks that mix multiple reasoning aspects in a single query, EO-Bench ensures that each question isolates a specific embodied reasoning skill, making evaluations interpretable and reliable.
Charming points
EO-Robotics distinguishes itself from prior embodied AI frameworks through three defining elements:
Unified Multimodal Transformer
EO-1 processes text, vision, and actions in a single stream rather than through disjointed modules. This unified design improves alignment across modalities and enables coherent reasoning-to-action pipelines.Interleaved Embodied Dataset
EO-Data1.5M structures multimodal episodes in temporal order, linking perception, reasoning, and action. The inclusion of flexible interleaved QA pairs with robot actions enriches cross-modal grounding and provides the model with nuanced spatial–temporal reasoning skills.Principled Benchmarking with EO-Bench
EO-Bench introduces a structured evaluation suite that disentangles reasoning categories. This not only allows researchers to identify bottlenecks in embodied intelligence—such as spatial reasoning, which is emphasized in the benchmark—but also sets a standard for transparent and interpretable comparisons.
Together, these design choices create a toolchain that goes beyond conventional VLAM approaches. EO-1 does not merely predict actions from observations; it integrates reasoning, perception, and control into a single generative process. This positions EO-Robotics as a platform for generalist embodied intelligence, where robots can flexibly adapt across tasks, environments, and modalities without requiring task-specific retraining.

EO-1 is my final example of how embodied foundation models are moving beyond narrow perception or control, toward systems that unify vision, language, and action into generalist frameworks for reasoning and robotics.
In Closing
