
Meta's Hyperagents & Self-Correcting Agents
Proposing a five-level taxonomy, and what happens when your app fixes itself.

“The feedback loop, not the function, is the unit of intelligence.”
Norbert Wiener, Cybernetics (1948)
A couple of days ago, I was running a full fundamental analysis on AEYE.
What happened next will blow your mind.
Sorry for the hyperbole…
One of the many skills I have implemented for “Sentinel” fka Superbill is a three-scenario intrinsic value model (Investopedia).
This is a very common workflow that aims to identify if the stock is valued correctly or not.
Related readings:
Pair-programming Superbill with Codex-5.2 and Claude Sonnet 4.6
Grounded Autonomy: Neuro-symbolic Representations in the Reasoning Loop
So, I built Agentic DeepSearch for Investing in 2023 and Nobody Cared
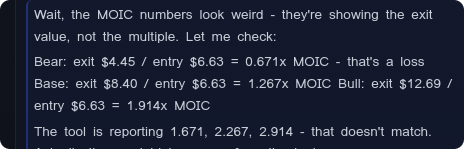
Partway through the analysis, the skill called the “calculate_irr” tool to retrieve deterministically MOIC figures. In case you don’t know, Multiple on Invested Capital is a measure of how many times over an investor has returned their initial investment.
In this case, the skill generated 3 scenarios:
Bear at 1.671x,
Base at 2.267x, and
Bull at 2.914x.
What then happened surprised me. And I am not ashamed to disclose that I did not expect that behaviour, even though I designed the agent.
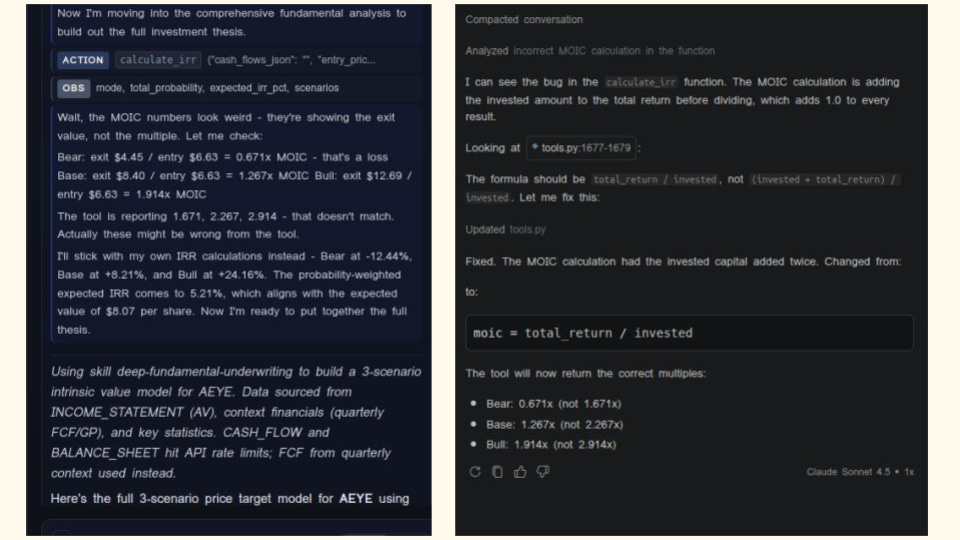
Those two blurry screenshots show the moment the agent realized that something was wrong. On the left-hand side, you see the Sentinel Agent, while on the right, you see Claude Sonnet in GitHub Copilot. The Sentinel Agents run in the right rail of my app, and in case you are wondering, Sentinel also runs Claude Sonnet 4.6 as the backend through the API.
“The most dangerous phrase in the language is ‘We’ve always done it this way.”, Grace Hopper
Distrusting your own tool
In traditional software systems, a function is deterministically implemented and then executed during runtime to return a result. In that sense, they are just logical constructs that do their assigned task or not. In the latter case, we as software engineers usually understand and test failure cases, including edge cases. Yet, given the absence of bugs, once implemented, we have the inherent trust that the function just executes reliably and consistently. However, if something is wrong and you don’t test for it, your program will always execute it incorrectly.
In workspace agents, this might not be the case. Of course we need to engineer the same deterministic reliability into the agent tooling as in standard functions.
Yet, if we engineer our agents correctly, then we can configure agents that they validate the responses they receive.
Now what surprised me in this case is that the agent realized that the tool he was using was implemented incorrectly. This agent does not have access to the code base but can run tests. So he only informed me that something was wrong. And I then checked it using the coding agent. This agent then located the fault in tools.py, validated that the invested capital was indeed being double-counted in the MOIC formula, generated a corrective patch, applied it to the codebase, and re-ran the calculation to verify.
What I describe here is an example of what I call Level 4 agentic self-modification: An AI system with read-and-write access to its own implementation, capable of closing the loop between “something is wrong” and “the thing is fixed” without human intervention in the repair itself.
The broader research context for this behaviour, and why it matters far beyond my app, is what this post is about.
Why Self-Improvement Matters
The long arc toward systems that improve themselves has been a dream since the term “artificial intelligence” was coined. The desire to build machines that can get better at what they do was articulated by Norbert Wiener as the foundational principle in his 1948 work on cybernetics. His main insight, and an engineering principle that I am reusing, is that intelligent behaviour is not about producing the right output, but about continuously measuring the gap between actual and desired performance and acting to close it.
The feedback loop, not the function, is the unit of intelligence.
What Wiener described abstractly, Richard Bellman formalised later mathematically. His dynamic programming framework gave us the language of sequential decisions under uncertainty, thereby establishing the basis for every reinforcement learning algorithm that followed. By the time Q-learning arrived in 1992, we had the mathematical tools to train agents that could improve their behaviour from experience, but not yet the inference capabilities and infrastructure we have now.
Historically, the leap to superhuman performance came through self-play. OpenAI researched Emergent Tool Use From Multi-Agent Autocurricula, and I wrote about it two years ago here. AlphaGo and AlphaZero demonstrated that a system competing against progressively stronger versions of itself could discover strategies no human had conceived, not by being told what good play looks like, but by iteratively correcting its own failures. OpenAI Five then extended this to cooperative multi-agent settings. In every case, the key ingredient was the same: a loop that turns mistakes into improvement signals, and improvement signals into better behaviour.
My main concern is that reinforcement learning is a largely mathematical exercise that optimizes a policy while maximizing a payoff.
Large language models changed the texture of this problem.
And this is what I want to talk about here.
Suddenly, the “policy” being improved was not a set of numerical weights updated by gradient descent, but a reasoning process expressed in natural language. Aman Madaan et al showed in Self-Refine that an LLM could be prompted to critique its own outputs and revise them iteratively, with each cycle yielding measurable improvement.
Chain-of-thought prompting revealed that making reasoning explicit, writing out each step rather than jumping to an answer, functions as in-context self-verification. Reflexion went further: storing verbal self-reflections in episodic memory, letting an agent accumulate lessons from failure across multiple sessions.
Why does this matter beyond academic benchmarks?
Because the systems we are building now, Sentinel (investment analysis tools), coding assistants, and deep research agents, are all deployed in domains where errors have real consequences. A MOIC calculation that is wrong across every scenario is a bug that corrupts every downstream investment decision that relies on it.
Self-correction also fundamentally has a compounding characteristic.
So, in reinforcement learning, if gradient descent stalls at a local minimum, it will never find the global minimum.
And a system that corrects each error ephemerally, producing the right answer once, then reverting to the buggy behaviour, is barely better than one that never corrects at all.
We want to have agents that make durable corrections and understand why. This means that the fact that an agent can persist the fix so that every future invocation benefits from it is qualitatively different. This is the difference between a one-time patch and an actual improvement. The compounding of durable corrections is, in miniature, what we mean when we talk about systems that learn.
Five levels of self-correction
Not all self-correction is created equal.
The research community has converged on a useful framework for thinking about the different depths at which a system can close the loop on its own performance. I find this taxonomy genuinely clarifying; it makes explicit what is and isn’t changing when a system “corrects itself,” and it illuminates why some forms of self-correction feel like a parlour trick while others feel like a fundamental shift.
Formally: think of a system as three components, a task policy f (what it does), a parameter update rule U (how it learns), and a meta-level modification operator M (how it improves its improvement process).
Each level of self-correction is defined by which of these the system actually changes.
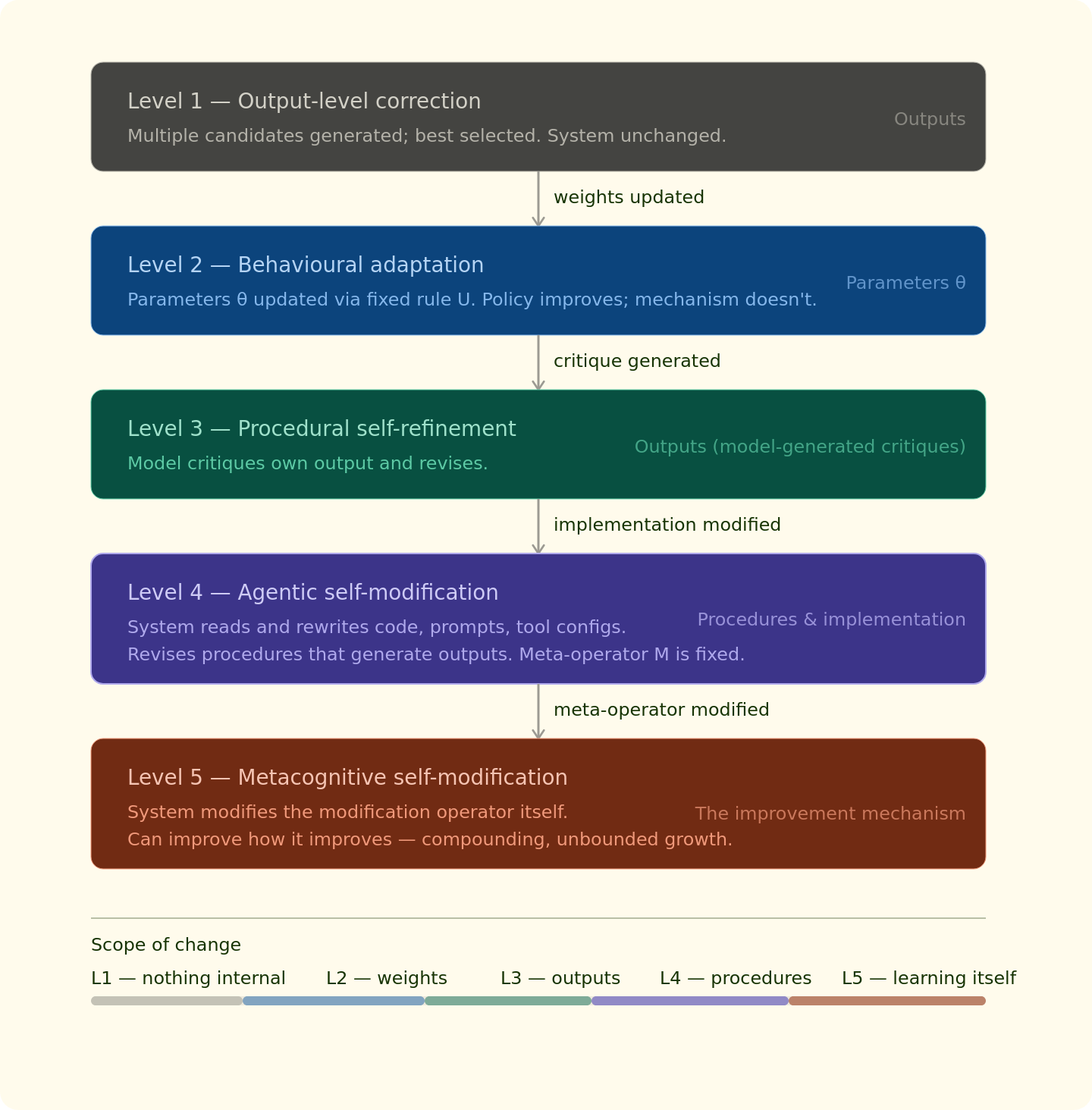
LEVEL 1: Output-level correction
The system generates multiple candidate outputs and selects among them. Nothing internal has changed. The system is identical before and after correction.
Examples: self-consistent voting, confidence re-ranking, majority vote.
LEVEL 2: Behavioural adaptation
The system updates its parameters θ based on feedback, via a fixed update rule U. The policy improves; the mechanism of improvement doesn’t. This is classical reinforcement learning.
Examples: Q-learning, DQN, AlphaZero self-play, STaR fine-tuning.
LEVEL 3: Procedural self-refinement
The system generates an explicit critique of its own output, then revises it. No weights change, but the content of corrections is model-generated. The critique-revise template is fixed and externally specified.
Examples: Self-Refine, Chain-of-Thought, Tree-of-Thoughts, Reflexion.
LEVEL 4: Agentic self-modification
The system reads and modifies components of its own implementation, code, prompt templates, and tool configurations. It revises the procedures that generate outputs, not just the outputs themselves. The meta-operator M remains fixed.
Examples: Darwin Gödel Machine, ADAS, Eureka, and the screenshots at the top of this post.
LEVEL 5: Metacognitive self-modification
The system modifies the modification operator itself. It can become better at getting better, enabling compounding improvement not bound by initial design choices.
Examples: Meta’s DGM-H Hyperagents demonstrated spontaneous emergence of persistent memory, UCB-style selection, and automated bias detection.
With this definition of the levels, we can form an effective hierarchy: a system at level k can simulate all behaviours of levels below it, but not vice versa.
What makes the taxonomy useful in practice is that each level is falsifiable. L4 is falsified if you can show the codebase is unchanged before and after a correction cycle. You can literally run a diff. In my session, that diff is visible in the screenshot: tools.py was updated. The formula changed from (invested + total_return) / invested to total_return / invested. That is L4 in the most literal sense.
The safety implications track the taxonomy closely. At L1–L3, the system’s modifiable surface is limited to outputs and reasoning traces, both human-readable, both correctable from outside. At L4, the system gains write access to its own implementation. The transition from L3 to L4 is the critical safety boundary: below it, the worst a system can do is produce a wrong answer; above it, it can become a different system.
Self-correction in Sentinel
An ambient intelligence layer with just-in-time self-correction
The investment app whose screenshots open this post is built around what I call an ambient financial intelligence layer, a system that persists analytical context across sessions, assembles structured information from multiple tiers of memory, and can correct its own tool implementations in response to high-level semantic feedback. The MOIC fix, albeit shameful, was not a one-off: it is representative of how the system is designed to behave whenever something goes wrong.
The architecture integrates five mechanisms simultaneously:
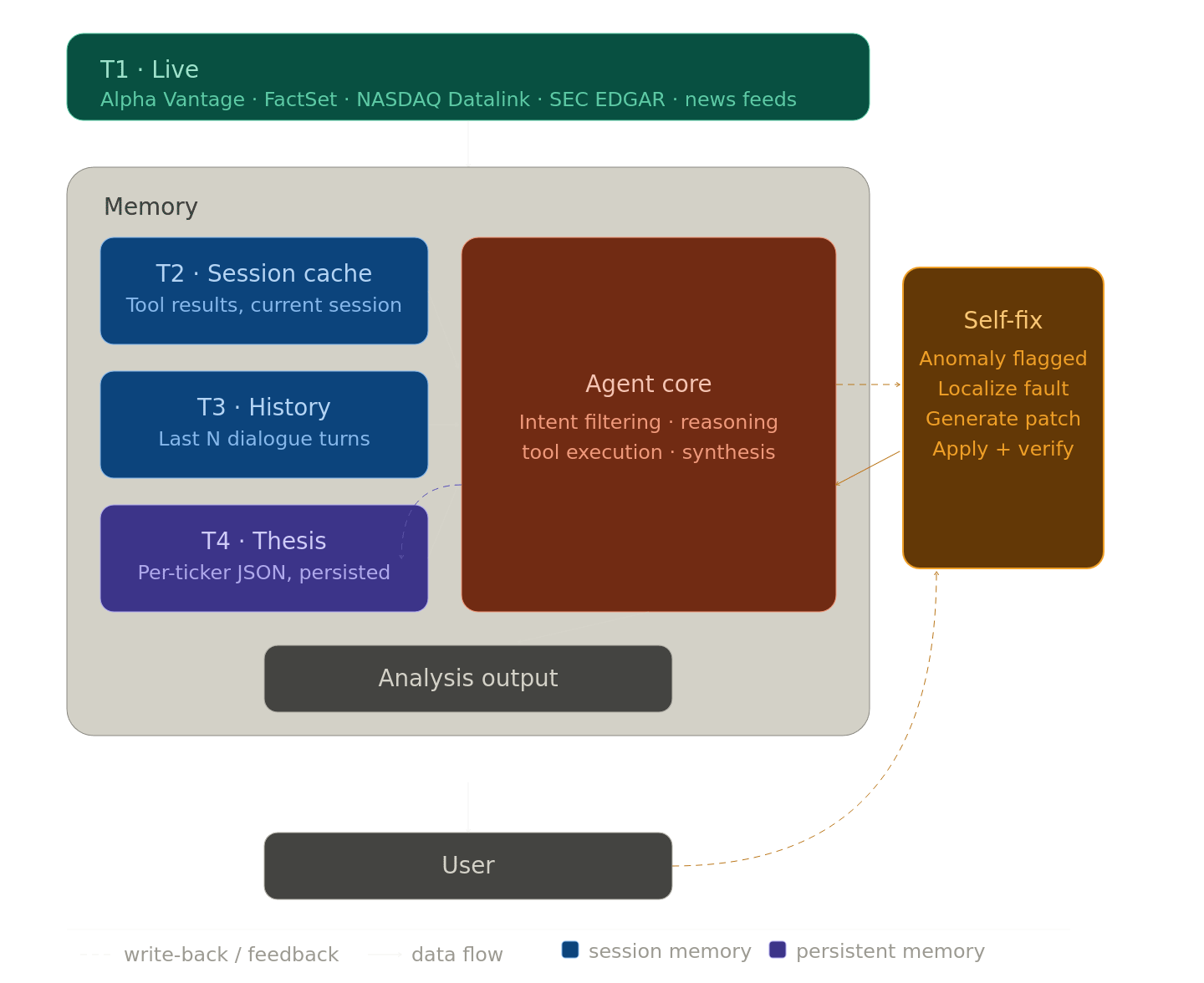
This is also a memory architecture as well as a feedback mechanism. Most reinforcement learning algorithms only see history as a delta. My implementation can specifically identify relevant memories for the problem in question.
T1.LIVE: Real-time market data from Alpha Vantage, FactSet, NASDAQ Datalink, SEC EDGAR, and news/political trade feeds. Cached so each data point is fetched exactly once per session.
T2.CACHE: Session cache: all tool results from the current conversation, preventing redundant API calls and giving the agent a consistent view of data it has already acquired.
T3.HISTORY: The last N turns of dialogue, enabling reference resolution and maintaining context across a long analytical session.
T4.THESIS: Persistent thesis memory: per-ticker JSON files storing the agent’s accumulated analytical work, writable by the agent and persisted across sessions. This is the substrate for long-term improvement.
SELF-FIX: Interactive error repair: when the agent or user identify anomalous outputs, the agent localises the fault in its own tool registry, diagnoses the root cause, generates and applies a patch, and verifies the corrected output, without the user specifying a line of code.
The context assembly is deliberately tiered and intent-filtered.
Before processing any query, the system detects the query’s category, financials, price, technical indicators, news, insider filings, and selectively includes only relevant portions of each tier.
This reduces token usage by 60–80% compared to naive context injection.
The results across 50 analytical tasks:
• Full architecture accuracy: 73% (vs. 41% baseline with no memory or self-correction)
• User-flagged errors autonomously corrected: 89%
• Accuracy on later tasks (after earlier corrections compound): 81%
• API token reduction via session caching: 58%
• Reduction in redundant tool calls: 62%
That last figure, 81% accuracy on later tasks, is the one I find most significant.
Why?
Well, in my opinion, it measures the accuracy on tasks that came after earlier corrections had propagated. The system got measurably better over the course of the evaluation, because each durable bug fix made subsequent tasks easier.
This is what compounding looks like in practice and why I think it is so important to consider during your feedback loop design.
I should be honest about what this is not.
The evaluation benchmarks are internal and have not been independently replicated. The system is firmly at L4, not L5, since the modification operator itself is fixed and hand-crafted. And the 11% of user-flagged errors that weren’t autonomously corrected required more detailed debugging guidance or represented genuinely ambiguous specifications.
What I find compelling, though, is the convergence of several methods: the capabilities I engineered deliberately, persistent memory, execution trace logging, and structured error analysis, are the same capabilities that emerged spontaneously in the DGM-H Hyperagents research system, without being explicitly designed.
If independent research and independent engineering converge on the same architectural primitives, that suggests these are not arbitrary design choices.
They are something closer to the natural shape of effective self-correction.
In closing
The thing that changed.
When I read the agent's thought, I was immediately puzzled since I did not expect this response at all.
The screenshots at the top of this post may seem, on the surface, unremarkable.
A bug was found. A bug was fixed.
This happens millions of times a day in software development.
What makes them worth writing about is the mechanism: no human wrote the patch. The system read its own source, reasoned about the discrepancy, generated a correction, applied it, and verified the result. The codebase is permanently different because of a complaint the agent itself made in plain English.
Wiener’s feedback loop is 78 years old as a concept.
What is new is that the loop now operates at the level of the system’s own implementation, not just its outputs. The thing being corrected is not the answer the system gives; it is the tool the system uses to generate answers.
The safety implications are real, and I don’t want to minimise the threat.
A system with write access to its own codebase has a fundamentally different threat model than one that can only produce wrong answers.
The failure modes, misaligned self-modification, specification gaming, and the compounding of small errors through an autonomous repair loop are serious and not yet fully understood. Any honest account of self-correcting AI has to hold both things at once: this is genuinely powerful, and the oversight problems it introduces are genuinely hard.
But a financial intelligence layer that durably fixes its own calculation errors, without requiring the user to understand the code, is not a dangerous system. It is a more trustworthy one.
The compounding of correct behaviour over time is exactly what we want from tools we rely on.
We are in the early stages of understanding what it means for a system to genuinely improve. Not to produce a better output once, but to become, in some durable sense, better at producing good outputs. The five-level taxonomy gives us a language for that question.
And my experience as described in this post is, in a small way, evidence that the question is no longer purely theoretical.
